Бытует мнение, что на электронных книгах с e-ink дисплеями, можно комфортно читать только текстовые книжки, где можно выставить большой шрифт, а вот pdf и тем более сканы в djvu читать практически невозможно, глаза сломаешь разбирать мелкие буквы на небольшом дисплее. Спешу вас разуверить, читать такие книги вполне можно комфортно.
Это у меня уже вторая электронная книга и прочитано на ней уже довольна много книг, объемных, большая часть из которых и составляет техническая литература, которую в fb2 формате не найдешь. С книгой которую я купил первой, шла замечательная утилита JaP (Just Another Printer), которая умела нарезать pdf и djvu на куски, для четных и не четных страниц можно было выставить свою рамку, так же можно было добавить контраста, и все это дело она сохраняло в формат моей книги wolf. Для хорошего качества книг, допустим купленных или качественно сосканированных этого вполне было достаточно, но сканы плохого качества, а таких было не мало, страницы прыгали на листе, поля разнились, так что приходилось чуть ли не для каждой страницы выставлять рамку отдельно.
Такое положение вещей мне быстро надоело и я написал скрипт, который режет станицу пополам и обрезает поля, это сильно упростило подготовку книг для чтения. Но в разных книгах был разный шрифт и формат страниц и если некоторые вполне было так комфортно читать, то бывали попадались книги большого формата и не сильно крупным шрифтом, их чтение уже было не столь комфортным. Тогда то и родилась идея порезать не на две части, а на три, ради эксперимента, и результат оказался вполне отличным. Визуально буквы стали крупнее из-за того что вытянулись в длину. И хотя казалось бы, что оставшись в ширину такими-же, это будет выглядеть не очень то. Но чтение, довольно подсознательный процесс, даже смотря на очень мелкий текст я не всматриваюсь в буквы, я мельком взглянул и понимаю его смысл уже, распознавание происходит автоматом. Причем если читаем книгу, а не отдельную фразу, то мы в контексте книги и подсознание уже примерно знает какую информацию и какие слова тут можно встретить, что то же улучшает процесс распознавания. Я читаю мелкий шрифт так же быстро как и крупный, если его конечно вообще хорошо видно, но психологически комфортнее читать текст с привычным для обычных книг текстом шрифта, поэтому такой хак проходит на ура, подсознание и так вполне способно распознать текст, но с крупными буквами мне теперь читать его комфортнее.
Внизу приведен сам код скрипта, он довольна прост и без излишеств, так как писался в основном для себя. Самые главные строчки в нем это обрезание полей, разрезание страницы на три части с помощью ImageMagic и увеличение резкости, т.к. после уменьшения размера картинки резкость теряется, еще можно для запущенных вариантов поиграть с контрастом. Работу скрипта проверял на Ubuntu 10.04, для работы должны быть установлены ImageMagic, libtiff, pdftk и DjvuLibre. Как показала практика, djvu несколько тяжеловат для моего ридера, а вот pdf встроенный xPdf читает просто на ура, скорость перелистывания в pdf-файлах размером более 300Мб на уровне того же fb2. Да кстати о размере, файлы получаются огромными от 100Мб и до 300 и больше даже, в принципе при сегодняшней цене на флешь память это не так критично. Пробовал уменьшать DPI но при 16 градациях это заметно становится, поэтому оставил как есть, может кто подскажет как уменьшить размер без заметных потерь в качестве, буду благодарен.
Собственно получившийся результат, на качество картинок не обращайте внимания, фотал на мыльницу, без вспышки, что бы исключить блики. Книга порезанная пополам, без полей:
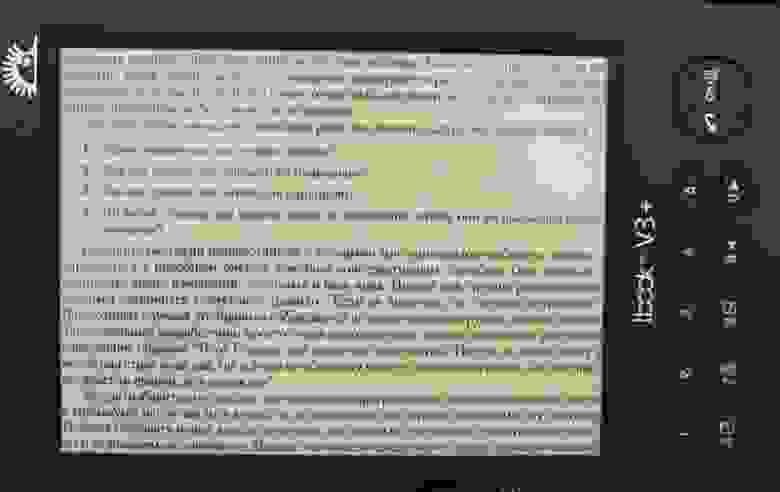
Книга со страницами порезанными на три части:

А вот для примера и книга со страницами порезанными на четыре части, по мне так уже немного перебор:

UPD: Пользователем alakond был предложен способ как несколько снизить размер выходного файла, для этого использовать PNG формат в качестве промежуточного формата изображений вместо Jpeg, в скрипт добавлены его изменения для выбора промежуточного формата.
Это у меня уже вторая электронная книга и прочитано на ней уже довольна много книг, объемных, большая часть из которых и составляет техническая литература, которую в fb2 формате не найдешь. С книгой которую я купил первой, шла замечательная утилита JaP (Just Another Printer), которая умела нарезать pdf и djvu на куски, для четных и не четных страниц можно было выставить свою рамку, так же можно было добавить контраста, и все это дело она сохраняло в формат моей книги wolf. Для хорошего качества книг, допустим купленных или качественно сосканированных этого вполне было достаточно, но сканы плохого качества, а таких было не мало, страницы прыгали на листе, поля разнились, так что приходилось чуть ли не для каждой страницы выставлять рамку отдельно.
Такое положение вещей мне быстро надоело и я написал скрипт, который режет станицу пополам и обрезает поля, это сильно упростило подготовку книг для чтения. Но в разных книгах был разный шрифт и формат страниц и если некоторые вполне было так комфортно читать, то бывали попадались книги большого формата и не сильно крупным шрифтом, их чтение уже было не столь комфортным. Тогда то и родилась идея порезать не на две части, а на три, ради эксперимента, и результат оказался вполне отличным. Визуально буквы стали крупнее из-за того что вытянулись в длину. И хотя казалось бы, что оставшись в ширину такими-же, это будет выглядеть не очень то. Но чтение, довольно подсознательный процесс, даже смотря на очень мелкий текст я не всматриваюсь в буквы, я мельком взглянул и понимаю его смысл уже, распознавание происходит автоматом. Причем если читаем книгу, а не отдельную фразу, то мы в контексте книги и подсознание уже примерно знает какую информацию и какие слова тут можно встретить, что то же улучшает процесс распознавания. Я читаю мелкий шрифт так же быстро как и крупный, если его конечно вообще хорошо видно, но психологически комфортнее читать текст с привычным для обычных книг текстом шрифта, поэтому такой хак проходит на ура, подсознание и так вполне способно распознать текст, но с крупными буквами мне теперь читать его комфортнее.
Внизу приведен сам код скрипта, он довольна прост и без излишеств, так как писался в основном для себя. Самые главные строчки в нем это обрезание полей, разрезание страницы на три части с помощью ImageMagic и увеличение резкости, т.к. после уменьшения размера картинки резкость теряется, еще можно для запущенных вариантов поиграть с контрастом. Работу скрипта проверял на Ubuntu 10.04, для работы должны быть установлены ImageMagic, libtiff, pdftk и DjvuLibre. Как показала практика, djvu несколько тяжеловат для моего ридера, а вот pdf встроенный xPdf читает просто на ура, скорость перелистывания в pdf-файлах размером более 300Мб на уровне того же fb2. Да кстати о размере, файлы получаются огромными от 100Мб и до 300 и больше даже, в принципе при сегодняшней цене на флешь память это не так критично. Пробовал уменьшать DPI но при 16 градациях это заметно становится, поэтому оставил как есть, может кто подскажет как уменьшить размер без заметных потерь в качестве, буду благодарен.
#!/bin/bash
# скрипт для преобразования PDF и DJVU файлов в формат для эклектронной книги 800x600
# использование: скрипт документ -in_[pdf|djvu] -out_[pdf|djvu] -img_format_[png|jpg]
in_format=$2
out_format=$3
img_format=$4
if [ "$img_format" = "-img_format_png" ];
then
img_format=png
else
img_format=jpg
fi
mask="*.*"
if [ "$in_format" = "-in_djvu" ];
then
# если это DJVU то приобразовываем его в многостраничный TIFF
ddjvu -format=tiff $1 1.tiff
# режем получившийся TIFF в по страницам
tiffsplit 1.tiff
rm 1.tiff
mask="x*.tif"
else
# режем PDF по страницам
pdftk $1 burst
mask="pg_*.pdf"
fi
pages=""
# обработать все страницы
for p in `ls -1 $mask`; do
# конвертируем страничку в JPG и преобразуем в оттенки серого
if [ "$in_format" = "-in_djvu" ];
then
convert -colorspace gray -normalize -contrast $p $p.${img_format}
else
convert -density 300 -colorspace gray -normalize -contrast $p $p.${img_format}
fi
rm $p
p=${p}.${img_format}
# обрезаем все поля автоматически
convert -trim +repage $p $p
# вырезаем верхнюю часть картинки
convert -gravity North -crop 100%x35% +repage $p 1_$p
# вырезаем вторую часть картинки
convert -gravity Center -crop 100%x35% +repage $p 2_$p
# вырезаем третью часть картинки
convert -gravity South -crop 100%x35% +repage $p 3_$p
rm $p
# меняем разрешение на 800х600
convert -scale 800x600! 1_$p 1_$p
convert -scale 800x600! 2_$p 2_$p
convert -scale 800x600! 3_$p 3_$p
# разворачиваем на 90 градусов
convert -rotate 90 1_$p 1_$p
convert -rotate 90 2_$p 2_$p
convert -rotate 90 3_$p 3_$p
# улучшаем качество картинки
convert -sharpen 0.01 1_$p 1_$p
convert -sharpen 0.01 2_$p 2_$p
convert -sharpen 0.01 3_$p 3_$p
# если выходной файл DJVU
if [ "$out_format" = "-out_djvu" ];
then
# конвертируем странички в djvu-формат
c44 -dpi 150 1_$p 1_$p.djvu
c44 -dpi 150 2_$p 2_$p.djvu
c44 -dpi 150 3_$p 3_$p.djvu
# список страничек
pages=${pages}' 1_'${p}'.djvu 2_'${p}'.djvu 3_'${p}'.djvu'
else
convert -define pdf:use-trimbox=true -density 200 1_$p 1_$p.pdf
convert -define pdf:use-trimbox=true -density 200 2_$p 2_$p.pdf
convert -define pdf:use-trimbox=true -density 200 3_$p 3_$p.pdf
# список страничек
pages=${pages}' 1_'${p}'.pdf 2_'${p}'.pdf 3_'${p}'.pdf'
fi
rm 1_$p 2_$p 3_$p
done
# создаем выходной файл книжки
if [ "$out_format" = "-out_djvu" ];
then
# собрать в единый DjVu
djvm -c out.djvu $pages
else
# собрать в единый PDF
pdftk $pages cat output out.pdf
fi
rm $pages
Собственно получившийся результат, на качество картинок не обращайте внимания, фотал на мыльницу, без вспышки, что бы исключить блики. Книга порезанная пополам, без полей:

Книга со страницами порезанными на три части:

А вот для примера и книга со страницами порезанными на четыре части, по мне так уже немного перебор:

UPD: Пользователем alakond был предложен способ как несколько снизить размер выходного файла, для этого использовать PNG формат в качестве промежуточного формата изображений вместо Jpeg, в скрипт добавлены его изменения для выбора промежуточного формата.









