
Мечта Карлсона сбывается
Помните из классики:
— Карлсон, ты знаешь, она хочет попасть в телевизор!
— Она? В телевизор?
— Да.
— Вот эта толстая домомучительница хочет залезть в самую маленькую коробочку?! Ничего не получится. Её надо будет сложить вчетверо!
А теперь представьте, что каждый день мы кладем в «самую маленькую коробочку», в информационно-справочную систему, по три реальные тележки текстовых документов, которые весят явно больше, чем Фрекен Бок. Плюс все эти документы нужно как-то добыть, сверить по многу раз, технологически обработать, а потом доставить пользователю в достоверном и актуальном виде. Об этом Карлсон мог только мечтать.
Сегодня мы совершим экскурсию по Производственному департаменту Консорциума «Кодекс» (ПД), сотрудники которого занимаются формированием начинки для профессиональных справочных систем «Кодекс» и «Техэксперт». Коллеги из разных подразделений из первых уст расскажут о нашем способе «наведения чистоты» в системе такого масштаба. Мы проследим весь жизненный путь документа от поиска до попадания к пользователю. Также выясним, есть ли у документа жизнь после смерти.
Взгляд изнутри

Системы «Кодекс» и «Техэксперт» — это профессиональные справочные системы с фондом нормативно-технической и законодательной информации в 13 млн. единиц (+ ~ 40 млн. документов судебной практики). Программный комплекс объединяет нормативные и консультационные материалы, а также аналитические сервисы по работе с документами.
Кто-то у нас пошутил, что в подвалах «Кодекса» есть собственная подземная фабрика гномиков, которые денно и нощно трудятся на благо развития системы. Действительно, объемы входящей документации и работ по сопровождению документов колоссальны: в месяц в тиражную систему попадают сотни экземпляров, так что было бы неплохо иметь такой сказочный ресурс. Но на самом деле процесс обработки документации – это кропотливый труд более 120 реальных и замечательных людей.
Специфика документов и их анализ
В нашем хранилище содержатся крупные блоки нормативно-технической документации (ГОСТ, ГОСТ Р, СП, СНиП, ГН, Р, ГЭСН и др.), нормативно-правовые акты органов государственной власти (законы, указы, постановления, законопроекты и др.), технологическая документация (чертежи, схемы и др.), аналитические материалы, классификаторы и словари, справочная информация. Существенным при этом является не только само содержание информации(текст документа можно найти и в Интернете), а её статус и актуальность– действует ли документ, а если действует – с какого времени, каковы были его предшественники, на основании каких документов вносились изменения и т.д. Чтобы система могла выполнять такие задачи, каждый документ необходимо анализировать вручную.
Процесс обработки
Процесс обработки документа различается в зависимости от типа документов. В широком смысле мы делим документы на нормативно-правовые (НП) и нормативно-технические (НТД). Технологические этапы их обработки напоминают собой конвейер. Из точки «А» документ движется в точку «Б», в руки к пользователю, причем каждый из них идет по собственному маршруту и контролируется на каждом этапе. Расскажем про каждый из них.
1. Поиск документа или жизнь до рождения

Чтобы документ был включен в информационно-справочную систему, сначала его нужно найти. Миром правят общественные связи, так что практически все новые документы, будь то изменение в законодательстве или в области технического регулирования, к нам поступают сразу. Чаще всего, в бумажном виде. Страшно признаться, но мы действительно грузим документы тележками, а типичный кабинет сотрудника производственного департамента напоминает башню старца Фура и гору бумаги, из которой зачастую торчат только уши ответственного сотрудника.
Практически день в день все важные новые документы вы можете увидеть в нашей системе. А как быть с более специфическими экземплярами? Например, с редким СНиПом или СП? Здесь всё начинается с Управления информационного обеспечения. Сотрудники данного подразделения ежедневно мониторят огромные пласты информации, из которой они должны выбрать важные и потенциально интересные для включения в систему документы.
Вот эта схема обработки документа на первом этапе была найдена у коллег.

Где найти документ?
Для каждого вида документов предусмотрен собственный источник поиска. Зачастую это официальные источники разработчиков профессиональной документации – если на их сайтах содержится интересный для пользователей документ, мы обязательно запросим разрешение на его публикацию и в нашей системе.

Если речь идет о нормативно-правовом документе, то здесь мы будем искать нужную информацию в официальных источниках органов госвласти, печатных изданиях, изданиях ведомств и т.д. Если мы ищем технический документ, то обращаемся к проектным институтам, НИИ и т.д.
Также у нас есть наработанная партнерская сеть – например, Российская национальная библиотека, которая регулярно поставляет нам старые документы. Кстати, в наших системах можно найти и совсем редкие авторские документы. Для этого существует Отдел информационно-стратегического развития, который ведет переговоры с организациями и заключает лицензионные договора с авторами.
В целом, Управление информационного обеспечения мониторит несколько сотен различных источников по всем отраслям.
Один старый лучше новых двух или как добыть недобываемое

В системы мы добавляем не только новые, но также и старые стандарты. Зачем? Потому что они нужны специалистам – архитекторам, реставраторам или врачам и т.д. Сложно представить себе ход проекта по реконструкции без изучения оригинальных чертежей.
А кто бы мог подумать, что до сих пор большой популярностью пользуются ретродокументы из Минздрава, которые очень трудно достать? Оказывается, многие технологии и стандарты, которые были введены в оборот еще на заре развития индустрии, до сих пор остались неизменными. Формально – старые, на деле – актуальные.
Специально для этой работы у нас в компании есть собственный «отряд партизан», который рыщет в поисках таких раритетов и половину своего рабочего времени проводит в архивах. Заказать ГОСТ из-за границы, раздобыть авторскую проектную документацию, если её разработчик уже давно умер или (высший пилотаж!) убедить очень Упорного Дедушку, научного сотрудника, выдать нужный экземпляр? Возможно почти всё.
Основная соль этой ответственной работы – построить эффективные личностные связи, договориться с правильным источником и добыть недобываемое. Только и всего :)
2. Первичный анализ
Ура! Мы нашли «тот самый» документ. Теперь мы должны проверить на актуальность оригинал и всю информацию, которая по нему имеется.
Если это нормативно-технический документ, то здесь мы узнаем его статус – действует или нет, а также сколько за его «жизнь» произошло изменений, где он был ранее опубликован и в каком виде должен появиться в нашей системе – полным текстом или в виде сканер-копии, а может, и в том и другом.
Если мы работаем с нормативно-правовым документом, то мы также уточняем все важные параметры.
Собранную информацию по любому виду документа мы фиксируем в специальном сопроводительном листе. Вместе с бумажной копией документа этот лист мы передадим дальше по технологической цепочке. Помечаем, в какие разделы каких баз данных документ нужно включить – наши коллеги на том конце цепочки положат соответствующую базу в тиражный информационный продукт, который пойдет пользователю.
Кстати, бывает и так, что мы находим какой-нибудь редкий документ, по которому невозможно определить его актуальность и статус. Так как материал теоретически может быть полезен пользователю, мы всё равно загружаем его в систему, однако делаем пометку, что в этом случае при обращении к документу пользователь должен увидеть соответствующее предупреждение.
Теперь нам осталось зарегистрировать документ в своей внутренней рабочей базе и отправить его на дальнейшую обработку.
Пока документ регистрируют, наслаждаемся видом из окна.

3. Перед включением в систему. Убойная сила устраняет нелегалов
Заготовка нашего документа – распечатанный текст с сопроводительным листом – теперь попадает в Управление базовой обработки информации (УБОИ), в отделы обработки нормативно-технической или нормативно-правовой информации. Здесь его уже ждут наши лучшие «оперативники».
Сейчас ответственный специалист создаст специальную карточку документа – своеобразный «паспорт», который будет присвоен документу на протяжении всего его существования в системе. Тут же документу дадут уникальный ID номер, укажут его категорию, тип и раздел. Теперь наш документ официально уже не «нелегал», а значит, он уже на своем пути к попаданию в систему.
Ставим вновь прибывшего на «маршрут следования». Ему предстоит попасть в руки ещё четырех разных специалистов.

4. Набивка и сверка
Нормативно-правовой документ
На данном этапе мы переводим бумажный оригинал в электронный вид.
Для этого нормативно-правовой документ сканируют и распознают. Полученный электронный текст оформляется в соответствии со стандартом предприятия. После этого документ распечатывают и несут на сверку корректорам. Важно пройтись глазами по каждой строке, потому что при распознавании текста могли быть допущены технические ошибки.
В среднем специалисты по набивке и сверке в год обрабатывает более километра печатного текста! Фото для оценки масштабов катастрофы. Цвет папки, в которой лежит документ, показывает, насколько срочно он должен быть обработан.

Нормативно-технический документ
Нормативно-технический документ обрабатывается аналогично, однако есть нюансы, ведь вместе с печатным текстом мы обрабатываем чертежи, макеты, таблицы и другие сопроводительные материалы. Для такого документа мы всегда создаем сканер-копию – подтверждение высшей достоверности.
Перед тем, как стать сканер-копией, изображение проходит стадию отстройки графики. Если графический элемент простой, то мы без проблем включаем его в систему. Если речь идет о сложном чертеже, о разветвленной схеме или о каком-нибудь документе, который много лет пролежал в архивах, то здесь уже целая команда специалистов работает над его качеством и удобочитаемостью.
Полнотекстовая версия НТД также отображается в системе: это нужно для того, чтобы пользователю были доступны все аналитические сервисы.
На этом же сканер-копия документа связывается с его карточкой.
Сканер-копия остается лежать в технологической базе, а текст мы тоже несем на корректорскую сверку.

5. Из корректорской сверки – к началу
После корректуры каждый документ возвращается на этап набивки. Там его радостно встретят и поправят все неточности, которые могли случайно прокрасться в текст. На этом же этапе к карточке документа, к его «паспорту», присоединяется электронный текст и все рисунки. Теперь мы можем видеть документ почти так, как его через некоторое время увидит пользователь. Опять распечатываем текст документа уже «из системы», несем корректорам (да, опять!!), которые вычитывают документ «палец в палец».
На фото — работа корректоров.

6. Обработка текстов скриптами
На этом этапе с текстом работают операторы баз данных. Они отвечают за то, чтобы были доступны все сервисные возможности по работе с документом, которые предоставляет система. Для этих операций используются соответствующие скрипты.
Из важных моментов – мы расставляем гиперссылки и проверяем, все ли они корректно работают.
Одни гиперсвязи отвечают за отношения между документами внутри системы: документы могут ссылаться друг на друга, причем обращаться либо к началу документа, либо к конкретному участку текста.
Другой вид гиперссылок отвечает за навигацию по изучаемому документу и обеспечивает переход на упоминаемый в тексте пункт или раздел.
Третий вид гиперссылокведет на внешние источники, такие как сайты, а также справочные материалы в наших системах и т.д. Всё это нужно расставить и проверить корректность работы скриптов-расстановщиков и якорей.
Здесь же мы добавляем в документ стили, иерархически раскрываемое оглавление, по которому можно осуществить поиск. Уточняем, понимает ли система статус документа, планируемые в нем изменения и др… Одним словом, смотрим, чтобы всё-всё-всё работало.

В свою очередь пользователь должен получить собственные возможности по работе с документом – например, получить ссылку на него в стороннее приложение, выгрузить текст к себе на компьютер, обратиться к всплывающей подсказке, поставить документ на контроль и т.д.
Нужно понимать, что технические средства не всегда могут верно распознавать, например, падежи, поэтому мы опять очень внимательно читаем текст.
Проверим, всё ли у нас в порядке. Гиперссылки расставились верно:
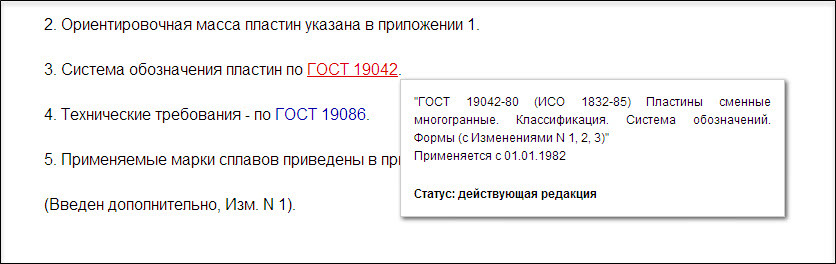
Смотрим в системе. Появилась информационная строка, гиперссылки также работают. Значит, можем идти дальше:
Указываем статус опубликования – кто, когда и где его опубликовал – и кладем его в базу для дальнейшей обработки.
7. Юридическая проверка и отправка пакетов документов пользователям
Вы думали, всё? Нет! Сейчас наши юристы будут проверять на соответствие оригиналам все информационные строки, статусы документа и прочую информацию. Теперь документ – свежий и красивый – лежит в нашей технологической базе. Со спокойной душой мы его отдаем на копирование по томам. Наш документ, вместе с его сородичами, упакуют по тематическим базам и по информационным продуктам, а потом отдадут пользователям.
Получается вот так:

8. Актуализация
На этом этапе обработка документа не заканчивается, так как в дальнейшем нужно поддерживать его актуальность. При подготовке новых документов юрист должен обратить внимание на то, не изменяют ли каким-то образом новые документы некоторые старые экземпляры, которые уже включены в нашу базу. К таким изменениям могут относиться изменения законодательства, поправки, возобновление и приостановка действия, разъяснения о применении и отмена документа.
Это настолько важные составляющие, что информацию о них мы предоставляем пользователю прямо в тот же день – он её получит вместе с ближайшим обновлением баз данных. Но нового текста он еще пока не увидит.
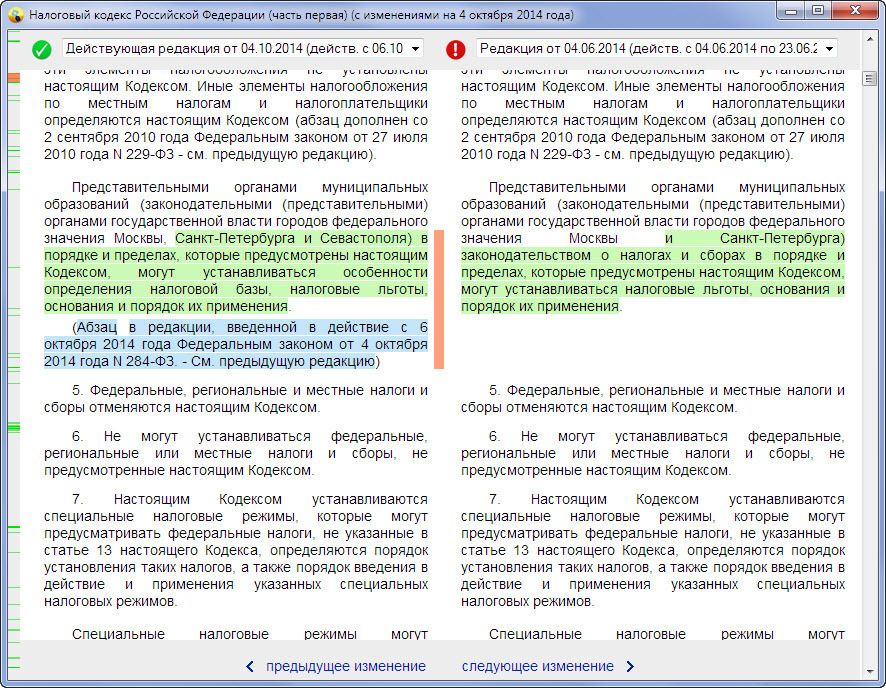
После того, как отправлена информация об оперативных изменениях в системе, за текст документа берется актуализатор-аналитик. Он создаст новую или будущую редакцию документа, поменяет текст, в соответствии с изменяющим документом, подготовит для документа сервисы «Сравнение редакций», «Обзор изменений», «Чистые тексты».
«Обзор изменений» покажет, что изменилось в текущей редакции, по сравнению с прошлой. Сервис «Сравнение редакций» позволит провести сравнение любых редакций документа между собой: система выделит все изменившиеся формулировки, так что специалисту будет легко с ними работать. Например:
Как федеральное, так и техническое законодательства довольно часто подвергаются изменениям. В связи с этим тексты документов содержат большое количество поясняющих материалов. С помощью сервиса «Чистые тексты» можно получить текст документа, свободный от таких примечаний, что удобно при чтении и печати документа.
Когда пользователь увидит документ?
Как только все предыдущие стадии обработки будут пройдены, не один, а сразу подборка всех новых документов попадает в ежедневное, еженедельное или ежемесячное обновление.
Периодичность обновления определяется динамичностью изменения контента и потребностями пользователей. Это означает, что после обновления при запуске системы пользователь сможет данный документ получить. Специально для тех, кто не хочет ждать, новые документы по результатам дня можно найти в сервисе «Горячие документы онлайн». Туда мы складываем онлайн-версии документов, которые предназначены для широкого просмотра.
Есть ли смерть после жизни?
По сути, если документ раз в жизни попал в систему, он оттуда уже не исчезнет никогда, так что ответ «нет» :) Могут вноситься только изменения – в строгом соответствии с нашим внутренним регламентом. Может измениться статус документа, его карточка и внутренние формулировки, добавятся примечания и комментарии, но сам документ будет доступен всегда, даже после утраты силы.
И напоследок
Сегодня мы познакомились с некоторыми рабочими процессами Производственного департамента. Теперь вы сами знаете, через сколько рук проходит один-единственный документ, перед тем как попасть «на стол» пользователю.
Очень важно отметить вклад каждого сотрудника в слаженную работу по строительству системы, а также степень его личной ответственности. Конечный продукт пойдет пользователям — это более 150 тыс. компаний, которые нам доверяют. Это миллионы профессионалов и миллионы ситуаций, для каждой из которых система должна предоставить самое компетентное решение.
В будущих публикациях и дальше будем рассказывать о нашей работе. Уже не только о документах, но и в целом о наших методах организации данных в профессиональных справочных системах.
До новых встреч!
