На третьем курсе бакалавра электронной инженерии мне требовалось выбрать диссертационный проект. Он мог быть чисто теоретическим, либо практическим, что включает в себя производство на свет демонстрационного продукта. Сердце легло ко второму варианту, ведь практические задания куда интересней скучной писанины.
В то время я увлекался робототехникой. Имел опыт строительства дронов и роботов поменьше, которые то следовали за линией по полу, то решали лабиринт за короткий промежуток времени. К тому же, мотивация была приподнята недавней поездкой в Лос-Анджелес на ежегодный VEX Robotics World Championship, где, к слову, не удалось занять призового места, но удалось зарядиться позитивной энергией на весь последующий год. В общем, решил я построить Hexapod своими руками, включая механику, электронику и код.

Половину лета я провел в поисках музы, точнее, пытался пересмотреть все имплементации и выбрать лучшее решение для дизайна шасси. Особое восхищение вызывали работы: PhantomX, A-pod и Intel Hexapod. Было решено черпать вдохновение из проекта PhantomX — и вот, что из этого получилось. Забегая вперед, хочу предупредить, что это все, чего я смог добиться от своего робота на год. Но мне был важен сам процесс и хороший диссертационный бал.
По окончанию лета, перед третьим курсом, я начал потихоньку расшатываться и решать административные вопросы, связанные с проектом. Мой лектор по Встроенным Системам, Доктор Тони Вилкокс, с радостью согласился стать супервайзером на год и помочь в достижении поставленной задачи. Нужно было решить вопрос с финансированием, так как глаз пал на отличные цифровые серво-проводы, Dynamixel AX-12A, стоимостью £26 за штуку, а всего требовалось 18 штук для полного счастья. Доктор Тони пообещал решить этот вопрос. На следующий день он заказал три серво-привода и дал задание — сконструировать одну ногу и продемонстрировать её работоспособность. После бесснежного английского Нового Года я вернулся в лабораторию с широкой улыбкой, ведь к этому времени у меня был на руках рабочий прототип ноги.
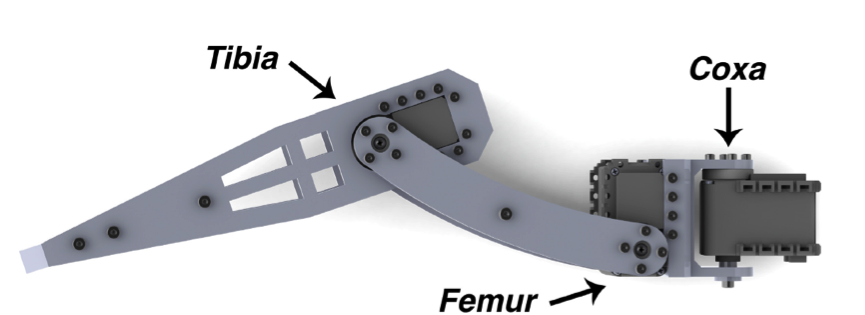
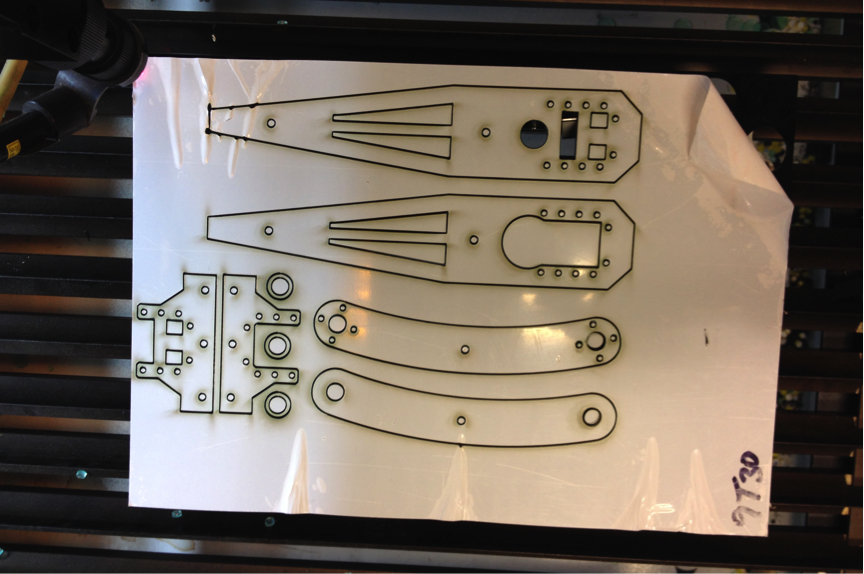
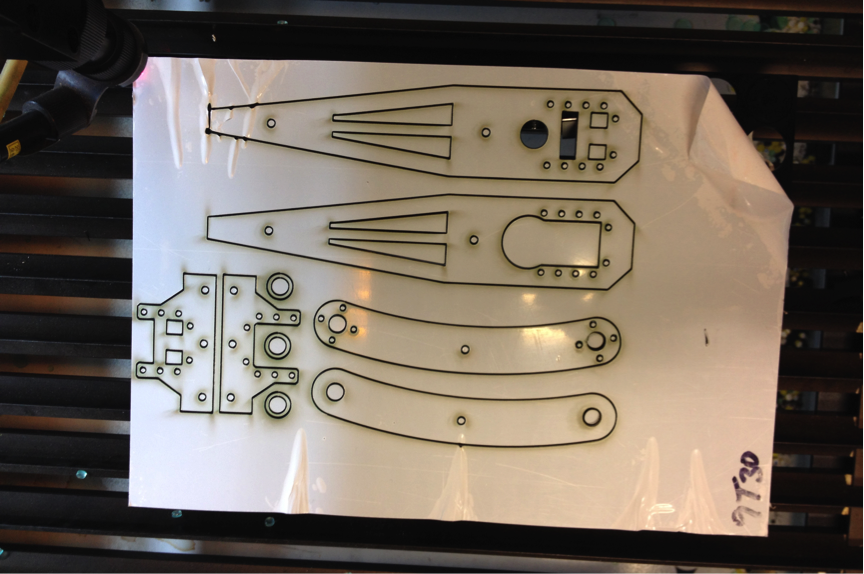
Большая часть шасси была выполнена из черного термопластика и вырезана с помощью лазерного станка.
Cкобка, соединяющая Coxa & Femur, была напечатана на 3D-принтере.

Прототип платы.
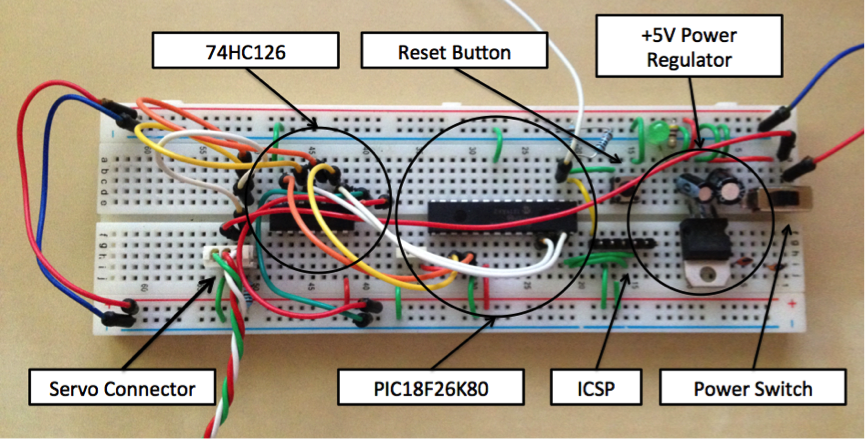
Как и обещал Тони, университет позаботился об остальных двенадцати моторах и через несколько дней я распаковывал коробки и обклеивал моторы номерными стикерами, чтобы не запутаться. Примерно в то же время начал переносить электронные наработки на печатные платы. Стоит отметить, что все платы были созданы вручную в стенах университета.

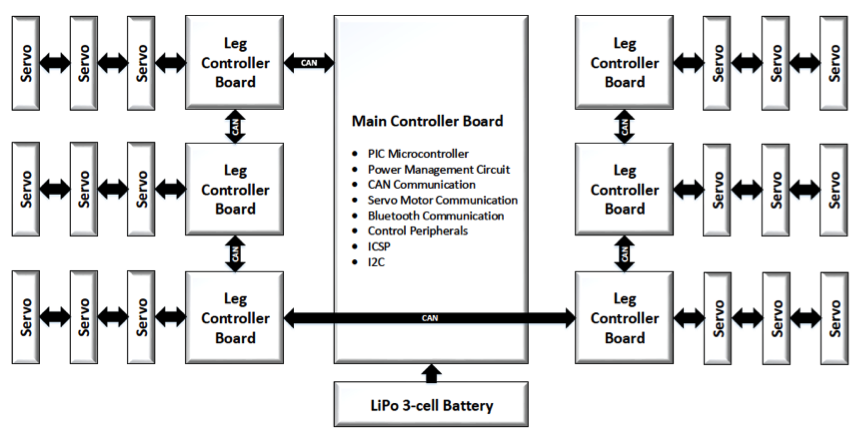
Чарт с объяснением начинки:
Робот управляется с терминала через Bluetooth:

Буду рад ответить на любые вопросы, связанные с материалом.
P.S.
В Англии курсовую работу на бакалавра называют диссертацией.
Если есть интерес можно покопаться в коде на github.
Электронные схемы на google drive.
Могу также выложить в открытый доступ CAD файлы, отпишитесь в комментариях если вам это интересно.
В то время я увлекался робототехникой. Имел опыт строительства дронов и роботов поменьше, которые то следовали за линией по полу, то решали лабиринт за короткий промежуток времени. К тому же, мотивация была приподнята недавней поездкой в Лос-Анджелес на ежегодный VEX Robotics World Championship, где, к слову, не удалось занять призового места, но удалось зарядиться позитивной энергией на весь последующий год. В общем, решил я построить Hexapod своими руками, включая механику, электронику и код.

Половину лета я провел в поисках музы, точнее, пытался пересмотреть все имплементации и выбрать лучшее решение для дизайна шасси. Особое восхищение вызывали работы: PhantomX, A-pod и Intel Hexapod. Было решено черпать вдохновение из проекта PhantomX — и вот, что из этого получилось. Забегая вперед, хочу предупредить, что это все, чего я смог добиться от своего робота на год. Но мне был важен сам процесс и хороший диссертационный бал.
По окончанию лета, перед третьим курсом, я начал потихоньку расшатываться и решать административные вопросы, связанные с проектом. Мой лектор по Встроенным Системам, Доктор Тони Вилкокс, с радостью согласился стать супервайзером на год и помочь в достижении поставленной задачи. Нужно было решить вопрос с финансированием, так как глаз пал на отличные цифровые серво-проводы, Dynamixel AX-12A, стоимостью £26 за штуку, а всего требовалось 18 штук для полного счастья. Доктор Тони пообещал решить этот вопрос. На следующий день он заказал три серво-привода и дал задание — сконструировать одну ногу и продемонстрировать её работоспособность. После бесснежного английского Нового Года я вернулся в лабораторию с широкой улыбкой, ведь к этому времени у меня был на руках рабочий прототип ноги.
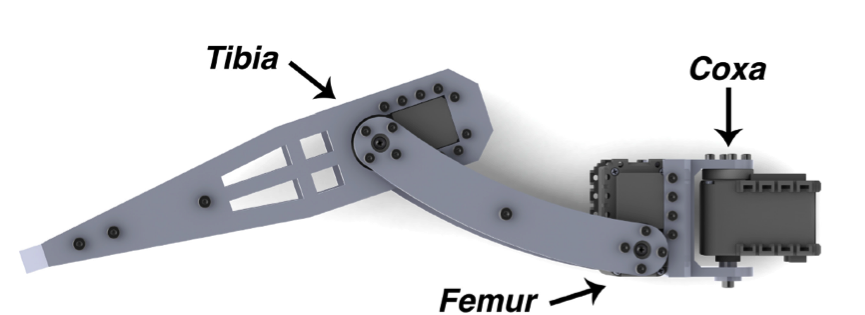
Большая часть шасси была выполнена из черного термопластика и вырезана с помощью лазерного станка.
Cкобка, соединяющая Coxa & Femur, была напечатана на 3D-принтере.

Прототип платы.
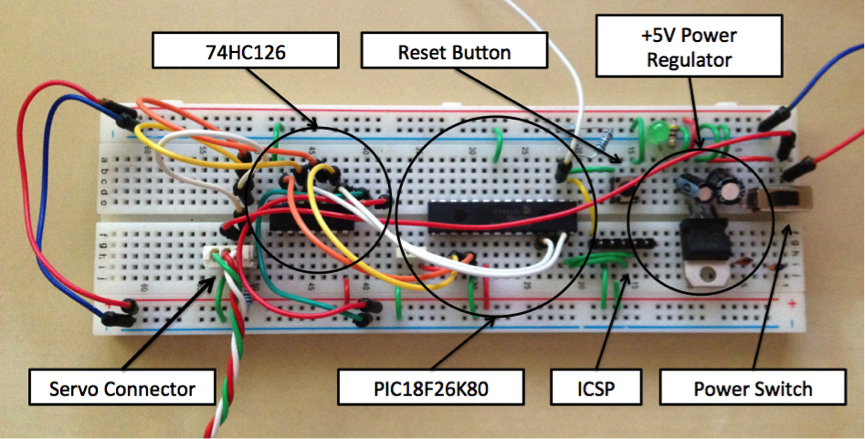
Как и обещал Тони, университет позаботился об остальных двенадцати моторах и через несколько дней я распаковывал коробки и обклеивал моторы номерными стикерами, чтобы не запутаться. Примерно в то же время начал переносить электронные наработки на печатные платы. Стоит отметить, что все платы были созданы вручную в стенах университета.

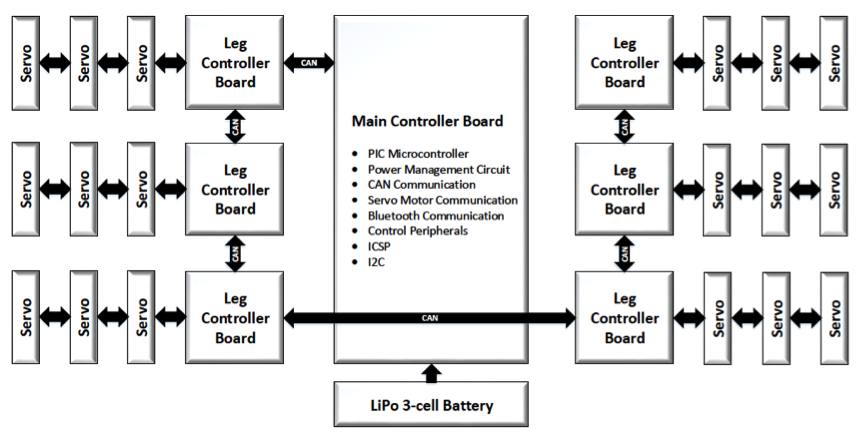
Чарт с объяснением начинки:
Робот управляется с терминала через Bluetooth:
Буду рад ответить на любые вопросы, связанные с материалом.
P.S.
В Англии курсовую работу на бакалавра называют диссертацией.
Если есть интерес можно покопаться в коде на github.
Электронные схемы на google drive.
Могу также выложить в открытый доступ CAD файлы, отпишитесь в комментариях если вам это интересно.







