Перед вами первая статья из цикла для тех, кто хочет узнать, как правильно делать и оформлять патентные исследования и отчитываться с их помощью перед заказчиком. Разбираемся в терминах, готовим шаблон отчета о патентных исследованиях.
Компания Центр речевых технологий (ЦРТ) временно не ведёт блог на Хабре
Учим компьютер различать звуки: знакомство с конкурсом DCASE и сборка своего аудио классификатора за 30 минут
8 мин
Статья написана совместно с ananaskelly.
Введение
Всем привет, хабр! Работая в Центре Речевых Технологий в Санкт-Петербурге, мы накопили немного опыта в решении задач классификации и детектирования акустических событий и решили, что готовы им с вами поделиться. Цель этой статьи — познакомить вас с некоторыми задачами и рассказать о соревновании по автоматической обработке звука “DCASE 2018”. Рассказывая вам о конкурсе, мы обойдемся без сложных формул и определений, связанных с машинным обучением, таким образом общий смысл статьи будет понятен широкой аудитории.
Для тех, кого в названии привлекла именно сборка классификатора, мы подготовили небольшой код на python, и по ссылке на гитхабе вы можете найти notebook, где мы на примере второго трека конкурса DCASE создаем простую сверточную сеть на keras для классификации аудиофайлов. Там мы немного рассказываем о сети и признаках, используемых для обучения, и как с помощью простой архитектуры получить близкий к baseline результат (MAP@3 = 0.6).
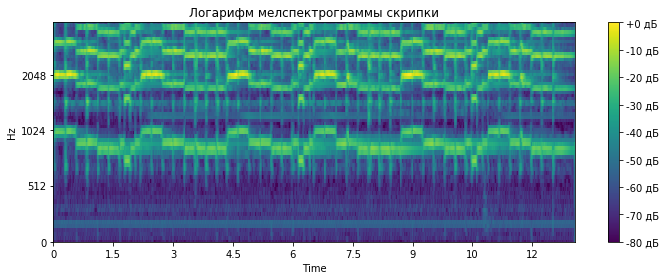
Дополнительно здесь будут описаны базовые подходы для решения задач (baseline), предложенные организаторами. Также в будущем появится несколько статей, где мы будем более подробно и в деталях рассказывать как о нашем опыте участия в соревновании, так и о решениях, предложенных другими участниками конкурса. Ссылки на эти статьи будут постепенно появляться здесь.
Антиспуфинг: как системы распознавания лиц противостоят мошенникам?
9 мин
В этой статье попробую обобщить информацию о существующих методах liveness detection, которые применяются для защиты от взлома систем распознавания лиц.

С развитием облачных технологий и веб-сервисов все больше транзакций перемещается в онлайн-среду. При этом более 50% онлайн транзакций (ритейл) совершаются с мобильных устройств.
Рост популярности мобильных транзакций не может не сопровождаться активным ростом киберпреступности.
От чего защищаем?
С развитием облачных технологий и веб-сервисов все больше транзакций перемещается в онлайн-среду. При этом более 50% онлайн транзакций (ритейл) совершаются с мобильных устройств.
Рост популярности мобильных транзакций не может не сопровождаться активным ростом киберпреступности.
Случаи онлайн-мошенничества на 81% вероятнее, чем мошенничество в точках продаж.
16,7 млн. личных данных американцев были украдены только за 2017 год (Javelin Strategy and Research). Ущерб от мошенничества с захватом аккаунтов составил $5,1 млрд.
В России, по данным Group-IB, за 2017 год хакеры украли у владельцев Android-смартфонов более миллиарда рублей, что на 136% больше, чем годом ранее.
Речевая аналитика для колл-центров на основе SOLR
7 мин
Хочу рассказать о нашем опыте разработки приложений на основе платформы полнотекстового поиска Apache Solr.
Перед нами стояла задача разработать систему речевой аналитики для контактных центров. В основе системы две базовых технологии: распознавание речи и индексированный поиск. Для распознавания мы использовали свои движки, а для индексации и поиска выбрали Solr.
Почему именно Solr? Собственных сравнительных исследований движков индексированного поиска мы не проводили, но внимательно ознакомились с мнением коллег. Конечно, выбор мог состояться и в пользу Elasticsearch или Sphinx, но, видимо, звезды в нашем проекте сложились в пользу Solr, его мы и “пилили”. Уже по ходу проекта мы определили, что имеющихся в Solr настроек достаточно для конфигурирования под наши задачи.
Перед нами стояла задача разработать систему речевой аналитики для контактных центров. В основе системы две базовых технологии: распознавание речи и индексированный поиск. Для распознавания мы использовали свои движки, а для индексации и поиска выбрали Solr.
Почему именно Solr? Собственных сравнительных исследований движков индексированного поиска мы не проводили, но внимательно ознакомились с мнением коллег. Конечно, выбор мог состояться и в пользу Elasticsearch или Sphinx, но, видимо, звезды в нашем проекте сложились в пользу Solr, его мы и “пилили”. Уже по ходу проекта мы определили, что имеющихся в Solr настроек достаточно для конфигурирования под наши задачи.
Разработка акустического датасета для обучения нейронной сети
13 мин
Однажды в интервью один всем известный российский музыкант сказал: “Мы работаем над тем, чтобы лежать и плевать в потолок”. Не могу не согласиться с этим утверждением, ведь то, что именно лень является движущей силой в развитии технологий, спору никакого быть не может. И действительно, только за последнее столетие мы перешли от паровых машин к цифровой индустриализации, и теперь искусственный интеллект, о котором писали фантасты и футурологи прошлого столетия, с каждым днём становится всё большей реальностью нашего мира. Компьютерные игры, мобильные устройства, умные часы и многое другое
Введение в задачу распознавания эмоций
6 мин
Распознавание эмоций – горячая тема в сфере искусственного интеллекта. К наиболее интересным областям применения подобных технологий можно отнести: распознавание состояния водителя, маркетинговые исследования, системы видеоаналитики для умных городов, человеко-машинное взаимодействие, мониторинг учащихся, проходящих online-курсы, носимые устройства и др.
В этом году компания ЦРТ посвятила этой теме свою летнюю школу по машинному обучению. В этой статье я постараюсь дать краткий экскурс в проблему распознавания эмоционального состояния человека и расскажу и подходах к ее решению.

ЦРТ и Университет ИТМО приглашают в Летнюю школу машинного обучения
2 мин
Лето — отличное время, чтобы отдохнуть и подтянуть профессиональные навыки. Поэтому мы открываем прием заявок в Летнюю школу машинного обучения, которая пройдет в Петербурге с 2 по 15 августа при поддержке Университета ИТМО. Заявки принимаем до 23 июля!
Студентов Школы, которые справятся с тестовым заданием и успешно пройдут конкурсный отбор, будет ждать масса положительных эмоций, новых знаний и возможностей для дальнейшего роста.
Студентов Школы, которые справятся с тестовым заданием и успешно пройдут конкурсный отбор, будет ждать масса положительных эмоций, новых знаний и возможностей для дальнейшего роста.
Битва титанов наших дней: спор В. Вапника и Л. Джейкела о будущем SVM и нейронных сетей
3 мин
Воспоминания о том, как спорили Нильс Бор с Альбертом Эйнштейном, а Джордж Вестингауз и Никола Тесла с Томасом Эдисоном, давно превратились в легенды. Эти научные дискуссии не забыты до сих, потому что, с одной стороны, разрешить их смогло только время. С другой стороны, их исход определил развитие технологий на десятилетия вперед. Существуют ли подобные дискуссии в наши дни? Существуют. И они столь же горячи и интересны, как и сто лет назад.
Пожалуй, самым интересным спором современности является спор Владимира Вапника (изобретателя метода опорных векторов или SVM — support vector machine), с Ларри Джейкелом, его боссом в компании “Bell Labs” и сторонником сверточных нейронных сетей.
ЦРТ объявляет конкурс по синтезу речи
1 мин

Приглашаем поучаствовать в конкурсе по синтезу живой русской речи на основе технологий глубоких нейронных сетей. Конкурс рассчитан на студентов старших курсов, молодых специалистов и всех желающих, интересующихся машинным обучением и речевыми технологиями. Победитель получит 100 000 рублей!
Участникам TTS challenge предстоит создать и обучить систему синтеза и озвучить с её помощью несколько десятков предложений русского текста. Базу голоса для обучения предоставляет ЦРТ, методы достижения результата участники выбирают самостоятельно. О том, как сделать нейросетевой синтез своими руками, мы недавно рассказывали в этой статье.
Нейросетевой синтез речи своими руками
12 мин
Синтез речи на сегодняшний день применяется в самых разных областях. Это и голосовые ассистенты, и IVR-системы, и умные дома, и еще много чего. Сама по себе задача, на мой вкус, очень наглядная и понятная: написанный текст должен произноситься так, как это бы сделал человек.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Речевая аналитика как инструмент управления KPI контакт-центра. Кейс «Ростелеком»
7 мин

Сегодня мы расскажем о том, как «Ростелеком Северо-Запад» повысил бизнес-показатели своего Единого Контакт-центра (ЕКЦ) с помощью инновационных технологий речевой аналитики. Подведены итоги консалтингового проекта, в рамках которого специалисты ЦРТ с помощью инструментов речевой аналитики Speech Analytics Lab проанализировали обращения клиентов в ЕКЦ «Ростелеком» и предложили методику улучшения качества обслуживания.
Зачем в КЦ нужна речевая аналитика?
ЕКЦ Северо-Западного филиала «Ростелеком» — огромная система, которая ежедневно обрабатывает тысячи обращений. При контроле качества супервизоры могут проанализировать только случайную выборку звонков, которая, как правило, составляет до 2% от общего числа обращений. А это не всегда даёт объективную картину.
С помощью инструментов речевой аналитики специалисты могут работать со 100% обращений. Для этого все диалоги ЕКЦ переводятся в текст и анализируются с помощью системы Speech Analytics Lab. Благодаря инструментам поиска в массивах неструктурированной речевой информации аналитик может отработать гипотезы (найти ключевые слова) на выборках в сотни тысяч фонограмм за несколько секунд.
На основе такого анализа можно разработать программу изменений для действующих в ЕКЦ процедур и процессов и оптимизировать системы самообслуживания (IVR, Личный кабинет, сайт).
Голосовая биометрия в контакт-центре банка. Кейс внедрения
5 мин

Всем привет! В прошлом году мы внедрили свое решение для голосовой верификации пользователей контакт-центров VoiceKey.Agent в Приорбанк (это один из крупнейших коммерческих банков Беларуси, входящий в австрийскую группу «Райффайзен») и теперь хотим рассказать вам о том, как мы это сделали и зачем это все понадобилось банку. На территории России и СНГ это второе внедрение голосовой биометрии в КЦ банка, поэтому мы стали практически первопроходцами.
Зачем банку биометрия
Не будем в очередной раз рассказывать, что традиционные технологии верификации пользователя (то есть подтверждение личности по знаниям: паролям, пин-кодам, кодовым словам и пр.) громоздки и не дают гарантированного результата. Крайне сложно удостовериться, действительно ли на другом конце провода находится тот самый человек, за которого он себя выдает. Оператор контакт-центра может лишь задавать уточняющие вопросы и сопоставлять голос человека с его полом, возрастом и другими особенностями. Достаточно очевидно, что для защиты финансовой информации этого мало.
Пиши голосом правильно
8 мин
Туториал

Всем привет!
У многих из нас мало опыта в так называемом голосовом письме – на диктофон свои мысли раньше записывали разве что психоаналитики. Теперь диктовка становится привычнее – к ней приучил сервис голосового набора в смартфонах. Участвуя как product owner в процессе создания продукта для распознавания русской слитной речи, общаясь с разработчиками алгоритмов и с клиентами, проводя различные тесты систем распознавания, наблюдая за тем, как пользователи диктуют свои тексты и имея свой большой опыт ввода текста в компьютер с помощью голоса, я набрал много интересных наблюдений. Чтобы лучше понимать, как правильно пользоваться автоматическим распознаванием речи давайте посмотрим, как устроено распознавание речи. Описание будет очень упрощенным, но зато поможет понять, какие ошибки люди совершают при диктовке. И еще: данную статью я буду писать с помощью диктовки, внося правки с клавиатуры только в тех местах, где без этого будет не обойтись.
Мобильное приложение «Читатель» теперь для Android
2 мин

Три года назад мы выпустили мобильное приложение «Читатель» для iOS и от многих пользователей нам стали приходить письма с вопросом, собираемся ли мы выпустить версию под Android. Разработка завершена, и состоялся официальный запуск «Читателя» в Google Play.
VoiceFabric: технология синтеза речи из облака
4 мин

Сегодня поговорим про перспективы и возможности облачного сервиса VoiceFabric для разработчиков и пользователей. Сервис озвучивает любую текстовую информацию синтезированным голосом в режиме реального времени. Под катом мы подробно расскажем о нашем синтезе, сценариях его использования (стандартных и не очень) и как подключить его к своим проектам, а так же о том, чем он уникален.
Вышла новая версия мобильного приложения «Читатель» для iOS
2 мин

Немного предыстории
Два года назад мы выпустили для iOS первую версию «Читателя» (Ссылка на iTunes). Это мобильное приложение, которое читает вслух загруженные в него книги и текстовые документы с помощью технологии синтеза русской речи. По сути дела, он позволяет озвучить в реальном времени любую книгу (.txt, .doc, .fb2). Книги озвучиваются прямо в мобильном устройстве, постоянный доступ в интернет при этом не нужен. За это время «Читатель» установили порядка 100 тысяч пользователей.
Конкурс разработчиков «Родная речь» — внимание, полуфинал!
1 мин
Уважаемые участники конкурса!
Полуфинальная выборка доступна для скачивания.
Обращаем ваше внимание, что пароль к выборке будет объявлен на сайте www.m2ies.com в день старта полуфинала 1.04.2014 в 14-00 по московскому времени.
Результаты работы вашей системы можно будет присылать до 14-00 2.04.2014.
Подробности — в конкурсной документации.
Удачи!

Полуфинальная выборка доступна для скачивания.
Обращаем ваше внимание, что пароль к выборке будет объявлен на сайте www.m2ies.com в день старта полуфинала 1.04.2014 в 14-00 по московскому времени.
Результаты работы вашей системы можно будет присылать до 14-00 2.04.2014.
Подробности — в конкурсной документации.
Удачи!
Конкурс разработчиков «Родная речь» — начинаем обратный отсчет!
1 мин
Важная информация для всех участников.
15 февраля в общий доступ выложена конкурсная база, с которой вам предстоит работать. Пароль для скачивания: SKT38G9MC28

Задание нужно выполнить до конца марта. Дедлайн отправки готового задания организаторам – 2 апреля. 3 апреля состоится полуфинал.
Напоминаем, что участники должны будут создать работоспособный алгоритм преобразования распознанной последовательности фонем в текст, соответствующий нормам русского языка. Подробнее о задаче в одном из предыдущих постов.
15 февраля в общий доступ выложена конкурсная база, с которой вам предстоит работать. Пароль для скачивания: SKT38G9MC28
Задание нужно выполнить до конца марта. Дедлайн отправки готового задания организаторам – 2 апреля. 3 апреля состоится полуфинал.
Напоминаем, что участники должны будут создать работоспособный алгоритм преобразования распознанной последовательности фонем в текст, соответствующий нормам русского языка. Подробнее о задаче в одном из предыдущих постов.
Конкурс «Родная речь» — неделя до старта!
1 мин
Дорогие участники конкурса разработчиков! До открытия доступа к конкурсной базе осталась всего одна неделя!

У вас еще семь дней на то, чтобы изучить задачу, пример, задать на форуме все интересующие вопросы и настроиться на творческий лад!
Не забудьте официально зарегистрироваться на портале m2ies.com: подробная инструкция здесь.
Напоминаем вам, что участники конкурса должны будут создать работоспособный алгоритм преобразования распознанной последовательности фонем в текст, соответствующий нормам русского языка. Подробнее о конкурсном задании можно прочитать в нашем предыдущем посте.
У вас еще семь дней на то, чтобы изучить задачу, пример, задать на форуме все интересующие вопросы и настроиться на творческий лад!
Не забудьте официально зарегистрироваться на портале m2ies.com: подробная инструкция здесь.
Напоминаем вам, что участники конкурса должны будут создать работоспособный алгоритм преобразования распознанной последовательности фонем в текст, соответствующий нормам русского языка. Подробнее о конкурсном задании можно прочитать в нашем предыдущем посте.
Распознай это! Конкурс «Родная речь» 2014
3 мин

Всем привет!
В прошлом посте мы анонсировали конкурс разработчиков «Родная речь-2014», участники которого должны будут создать работоспособный алгоритм преобразования распознанной последовательности фонем в текст, соответствующий нормам русского языка.
Регистрация уже началась, и чтобы помочь сомневающимся определиться с решением: принимать ли участие, я попробую объяснить, что же нужно сделать в рамках конкурса.