К сожалению, для шахмат пока нет лучших алгоритмов, чем перебор очень многих позиций. Правда, перебор порядком (и не одним) оптимизированный, но все же это большой перебор. Для поиска ответного хода строится дерево с исходным ходом в корне, ребрами — ходами-ответами и узлами — новыми позициями.
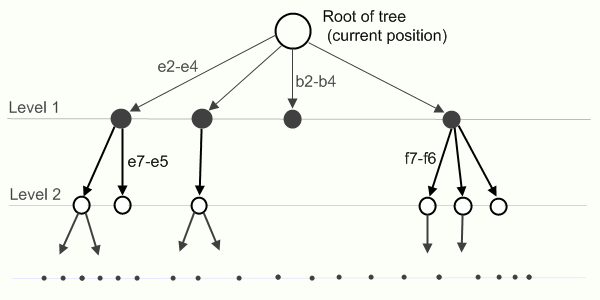
Как в элементарных алгоритмах выбирается следующий ход объяснить просто. На своем ходе вы выбираете такой ход (по вашему мнению), который принесет наибольшую пользу (максимизирует вашу выгоду), а противник на очередном своем ходе старается выбрать ход, который принесет ему больше всего пользы (максимизирует его выгоду и минимизирует вашу). Алгоритм с таким принципом называется минимакс. На каждом этапе вы присваиваете каждому узлу в дереве оценку позиции (об этом потом) и на своем ходе ее максимизируете, а на ходе противника — минимизируете. Алгоритм во время работы должен пройти по всем узлам дерева (то есть по всем возможный игровым позициям в игре), то есть совсем непригоден по времени.
Следующее его усовершенствование — альфа-бета отсечение (метод веток и границ).
Из названия следует, что в алгоритме проводится отсекание по каким-то двум параметрам — альфа и бета. Главная идея отсечения в том, что теперь мы будем держать интервал отсечений (нижняя и верхняя границы — альфа и бета соответственно — ваш К.О.) и оценки всех узлов, какие не попадают в интервал снизу мы рассматривать не будем (так как они не влияют на результат — это просто худшие ходы, чем уже найденный), а сам интервал будем сужать по мере нахождения лучших ходов. Хотя и альфа-бета отсечение намного лучше минимикса, все же время его работы тоже очень большое. Если принять, что в середине партии в одной стороны есть приблизительно 40 разных ходов, то время алгоритма можно оценить как O(40^P), где P — глубина дерева ходов. Конечно, при минимаксе может быть такая последовательность рассмотрения ходов, когда мы не будем делать никаких отсечений, тогда альфа-бета отсечение просто превратится в минимакс. В лучшем случае с помощью альфа-бета отсечения можно избежать проверки корня из числа всех ходов в минимаксе. Для того, чтоб избежать долгого времени работы (при такой О-большое сложности алгоритма), перебор в дереве делают на какую-то фиксированную величину и там проводят оценку узла. Вот эта оценка есть очень великое приближение к реальной оценке узла (то есть, перебора до конца дерева, а там результат — «выиграл, проиграл, ничья»). Насчет оценки узла есть просто кипа различных методик (можно прочесть в линках в конце статьи). Если кратко — то, естественно, подсчитываю материал игрока (согласно одной системе — целыми числами пешка — 100, конь и слон — 300, ладья — 500, ферзь — 900; согласно другой системе — действительными в частях от единицы) + позиция на доске данного игрока. Насчет позиции — то здесь начинается один из кошмаров написания шахмат, так как скорость работы проги будет в основном зависеть от оценочной функции и, если точнее, то от оценки позиции. Тут уже кто во что горазд. За спаренных тур игроку +, за прикрытость короля своими пешками +, за пешку возле другого конца доски + и т.д., а минусуют позицию висячие фигуры, открытый король и т.д. и т.п. — факторов можно написать кучу. Вот для оценки позиции в игре строится оценка позиции игрока, что делает ход, и от нее отнимается оценка соответствующей позиции противника. Как говорят, одна фотография иногда лучше тысячи слов, и, может, кусок кода на псевдо C# тоже будет лучше объяснений:
Думаю, не будут излишними некоторые объяснения насчет кода:
Пример использования метода:
где MateValue — достаточно большое число.
Параметр max_depth — максимальная глубина, на которую опустится алгоритм в дереве. Следует иметь в виду, что псевдокод чисто демонстративный, но вполне рабочий.
Вместо того, чтоб придумать новый алгоримт, люди, продвигающие альфа-бета отсечение, придумали много различных эвристик. Эвристика — просто небольшой хак, который иногда делает очень большой выигрыш в скорости. Эвристик для шахмат есть очень много, всех не пересчитаешь. Я приведу лишь основные, остальные можно найти в линках в конце статьи.
Во-первых, применяется очень известная эвристика «нулевой ход». В спокойной позиции противнику дают сделать два хода вместо одного и после этого рассматривают дерево на глубину (depth-2), а не (depth-1). Если после оценки такого поддерева окажется, что у текущего игрока все равно есть преимущество, то нет смысла рассматривать поддерево далее, так как после своего следующего хода игрок только сделает свою позицию лучше. Так как перебор полиномиальный, то выигрыш в скорости ощутимый. Иногда бывает так, что противник выровняет свое преимущество, тогда надо рассматривать все поддерево до конца. Пустой ход надо делать не всегда (например, когда один из королей под шахом, в цугцванге или в ендшпиле).
Далее, используется идея сначала сделать ход, в котором будет взятие фигуры противника, которая сделала последний ход. Так как почти все ходы во время переборатупые не очень разумные, то такая идея сильно сузит окно поиска еще в начале, тем самым отсекая много ненужных ходов.
Также известна эвристика истории или служба лучших ходов. Во время перебора сохраняются лучшие ходы на данном уровне дерева, и при рассмотрении позиции сначала можно попробовать сделать такой ход для данной глубины (базируется на идее, что на равных глубинах в дереве очень часто делают одинаковые лучшие ходы).
Известно, что такое своеобразное кеширование ходов улучшило производительность советской проги Каисса в 10 раз.
Также есть некоторые идеи насчет генерации ходов. Сначала рассматривают выигрышные взятия, то есть такие взятия, когда фигура с меньшой оценкой бьет фигуру с большей оценкой. Потом рассматривают promotions (когда пешку на другом конце доски можно заменить на более сильную фигуру), затем равные взятия и затем ходы с кеша эвристики истории. Остальные ходы можно отсортировать за контролем над доской или каким-то другим критерием.
Все было бы хорошо, если бы альфа-бета отсечение гарантировано давало бы лучший ответ. Даже учитывая долгое время на перебор. Но не тут то было. Проблема в том, что после перебора на фиксированную величину проводится оценка позиции и все, а, как оказалось, в некоторых игровых позициях нельзя прекращать перебор. После многих попыток выяснилось, что перебор можно прекращать только в спокойных позициях. Поэтому в основном переборе дописали дополнительный перебор, в котором рассматриваются только взятия, promotions и шахи (называется форсированный перебор). Также заметили, что некоторый позиции с разменом в середине также надо рассматривать поглубже. Так появились идеи насчет extensions і reductions, то есть углублений и укорачиваний дерева перебора. Для углублений найболее подходящие позиции типа ендшпиля с пешками, ухода от шаха, размен фигуры в середине перебора и т.д. Для укорачиваний подходят «абсолютно спокойные» позиции. В советской программе Каисса форсированный перебор был немного особенным — там после взятия во время перебора сразу начинался форсированный и его глубина не ограничивалась (так как за некоторое время он сам себя исчерпает в спокойной позиции).
Как говорил Энтони Хоар: "Premature optimization is the root of all evil in programming." (примечание: для тех, кто считает, что данная цитата принадлежит Кнуту, есть интересные дискусии тут и тут). В шахматном переборе, где будет относительно большая глубина рекурсии думать об оптимизациях надо, но очень осторожно.
Тут тоже есть несколько общих идей:
В статье была использована информация с некоторых ресурсов:
P.S. Вся теория была мной использована на практике и некоторое время существовал несложный rest-вебсервис на PHP для шахмат онлайн + программа на C# (использовался .NET Remoting для сетевой игры), но теперь сайт не рабочий и когда будет время, хочу перенести на RubyOnRails.
P.P.S. Кому интересно — проект теперь живет на гуглокоде и апгрейдится, когда у меня есть время. Кто захочет код предыдущей версии — могу выслать.
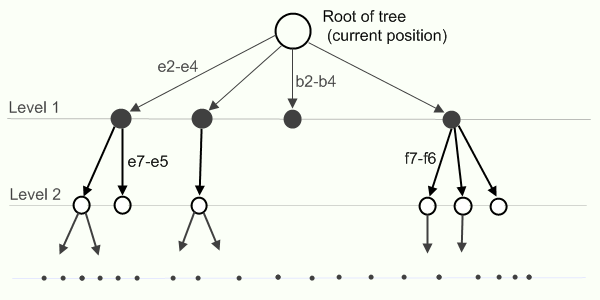
Как в элементарных алгоритмах выбирается следующий ход объяснить просто. На своем ходе вы выбираете такой ход (по вашему мнению), который принесет наибольшую пользу (максимизирует вашу выгоду), а противник на очередном своем ходе старается выбрать ход, который принесет ему больше всего пользы (максимизирует его выгоду и минимизирует вашу). Алгоритм с таким принципом называется минимакс. На каждом этапе вы присваиваете каждому узлу в дереве оценку позиции (об этом потом) и на своем ходе ее максимизируете, а на ходе противника — минимизируете. Алгоритм во время работы должен пройти по всем узлам дерева (то есть по всем возможный игровым позициям в игре), то есть совсем непригоден по времени.
Следующее его усовершенствование — альфа-бета отсечение (метод веток и границ).
Из названия следует, что в алгоритме проводится отсекание по каким-то двум параметрам — альфа и бета. Главная идея отсечения в том, что теперь мы будем держать интервал отсечений (нижняя и верхняя границы — альфа и бета соответственно — ваш К.О.) и оценки всех узлов, какие не попадают в интервал снизу мы рассматривать не будем (так как они не влияют на результат — это просто худшие ходы, чем уже найденный), а сам интервал будем сужать по мере нахождения лучших ходов. Хотя и альфа-бета отсечение намного лучше минимикса, все же время его работы тоже очень большое. Если принять, что в середине партии в одной стороны есть приблизительно 40 разных ходов, то время алгоритма можно оценить как O(40^P), где P — глубина дерева ходов. Конечно, при минимаксе может быть такая последовательность рассмотрения ходов, когда мы не будем делать никаких отсечений, тогда альфа-бета отсечение просто превратится в минимакс. В лучшем случае с помощью альфа-бета отсечения можно избежать проверки корня из числа всех ходов в минимаксе. Для того, чтоб избежать долгого времени работы (при такой О-большое сложности алгоритма), перебор в дереве делают на какую-то фиксированную величину и там проводят оценку узла. Вот эта оценка есть очень великое приближение к реальной оценке узла (то есть, перебора до конца дерева, а там результат — «выиграл, проиграл, ничья»). Насчет оценки узла есть просто кипа различных методик (можно прочесть в линках в конце статьи). Если кратко — то, естественно, подсчитываю материал игрока (согласно одной системе — целыми числами пешка — 100, конь и слон — 300, ладья — 500, ферзь — 900; согласно другой системе — действительными в частях от единицы) + позиция на доске данного игрока. Насчет позиции — то здесь начинается один из кошмаров написания шахмат, так как скорость работы проги будет в основном зависеть от оценочной функции и, если точнее, то от оценки позиции. Тут уже кто во что горазд. За спаренных тур игроку +, за прикрытость короля своими пешками +, за пешку возле другого конца доски + и т.д., а минусуют позицию висячие фигуры, открытый король и т.д. и т.п. — факторов можно написать кучу. Вот для оценки позиции в игре строится оценка позиции игрока, что делает ход, и от нее отнимается оценка соответствующей позиции противника. Как говорят, одна фотография иногда лучше тысячи слов, и, может, кусок кода на псевдо C# тоже будет лучше объяснений:
enum CurentPlayer {Me, Opponent};
public int AlphaBetaPruning (int alpha, int beta, int depth, CurrentPlayer currentPlayer)
{
// value of current node
int value;
// count current node
++nodesSearched;
// get opposite to currentPlayer
CurrentPlayer opponentPlayer = GetOppositePlayerTo(currentPlayer);
// generates all moves for player, which turn is to make move
/ /moves, generated by this method, are free of moves
// after making which current player would be in check
List<Move> moves = GenerateAllMovesForPlayer(currentPlayer);
// loop through the moves
foreach move in moves
{
MakeMove(move);
++ply;
// If depth is still, continue to search deeper
if (depth > 1)
value = -AlphaBetaPruning (-beta, -alpha, depth - 1, opponentPlayer);
else
// If no depth left (leaf node), evalute that position
value = EvaluatePlayerPosition(currentPlayer) - EvaluatePlayerPosition(opponentPlayer);
RollBackLastMove();
--ply;
if (value > alpha)
{
// This move is so good that caused a cutoff of rest tree
if (value >= beta)
return beta;
alpha = value;
}
}
if (moves.Count == 0)
{
// if no moves, than position is checkmate or
if (IsInCheck(currentPlayer))
return (-MateValue + ply);
else
return 0;
}
return alpha;
}
Думаю, не будут излишними некоторые объяснения насчет кода:
- GetOppositePlayerTo() просто меняет CurrentPlayer.Me на CurrentPlayer.Opponent і наоборот
- MakeMove() делает следующий ход из списка ходов
- ply — глобальная переменная (часть класса), которая держит в себе количество полуходов, сделанных на данной глубине
Пример использования метода:
{
ply = 0;
nodesSearched = 0;
int score = AlphaBetaPruning (-MateValue, MateValue, max_depth, CurrentPlayer.Me);
}
где MateValue — достаточно большое число.
Параметр max_depth — максимальная глубина, на которую опустится алгоритм в дереве. Следует иметь в виду, что псевдокод чисто демонстративный, но вполне рабочий.
Вместо того, чтоб придумать новый алгоримт, люди, продвигающие альфа-бета отсечение, придумали много различных эвристик. Эвристика — просто небольшой хак, который иногда делает очень большой выигрыш в скорости. Эвристик для шахмат есть очень много, всех не пересчитаешь. Я приведу лишь основные, остальные можно найти в линках в конце статьи.
Во-первых, применяется очень известная эвристика «нулевой ход». В спокойной позиции противнику дают сделать два хода вместо одного и после этого рассматривают дерево на глубину (depth-2), а не (depth-1). Если после оценки такого поддерева окажется, что у текущего игрока все равно есть преимущество, то нет смысла рассматривать поддерево далее, так как после своего следующего хода игрок только сделает свою позицию лучше. Так как перебор полиномиальный, то выигрыш в скорости ощутимый. Иногда бывает так, что противник выровняет свое преимущество, тогда надо рассматривать все поддерево до конца. Пустой ход надо делать не всегда (например, когда один из королей под шахом, в цугцванге или в ендшпиле).
Далее, используется идея сначала сделать ход, в котором будет взятие фигуры противника, которая сделала последний ход. Так как почти все ходы во время перебора
Также известна эвристика истории или служба лучших ходов. Во время перебора сохраняются лучшие ходы на данном уровне дерева, и при рассмотрении позиции сначала можно попробовать сделать такой ход для данной глубины (базируется на идее, что на равных глубинах в дереве очень часто делают одинаковые лучшие ходы).
Известно, что такое своеобразное кеширование ходов улучшило производительность советской проги Каисса в 10 раз.
Также есть некоторые идеи насчет генерации ходов. Сначала рассматривают выигрышные взятия, то есть такие взятия, когда фигура с меньшой оценкой бьет фигуру с большей оценкой. Потом рассматривают promotions (когда пешку на другом конце доски можно заменить на более сильную фигуру), затем равные взятия и затем ходы с кеша эвристики истории. Остальные ходы можно отсортировать за контролем над доской или каким-то другим критерием.
Все было бы хорошо, если бы альфа-бета отсечение гарантировано давало бы лучший ответ. Даже учитывая долгое время на перебор. Но не тут то было. Проблема в том, что после перебора на фиксированную величину проводится оценка позиции и все, а, как оказалось, в некоторых игровых позициях нельзя прекращать перебор. После многих попыток выяснилось, что перебор можно прекращать только в спокойных позициях. Поэтому в основном переборе дописали дополнительный перебор, в котором рассматриваются только взятия, promotions и шахи (называется форсированный перебор). Также заметили, что некоторый позиции с разменом в середине также надо рассматривать поглубже. Так появились идеи насчет extensions і reductions, то есть углублений и укорачиваний дерева перебора. Для углублений найболее подходящие позиции типа ендшпиля с пешками, ухода от шаха, размен фигуры в середине перебора и т.д. Для укорачиваний подходят «абсолютно спокойные» позиции. В советской программе Каисса форсированный перебор был немного особенным — там после взятия во время перебора сразу начинался форсированный и его глубина не ограничивалась (так как за некоторое время он сам себя исчерпает в спокойной позиции).
Как говорил Энтони Хоар: "Premature optimization is the root of all evil in programming." (примечание: для тех, кто считает, что данная цитата принадлежит Кнуту, есть интересные дискусии тут и тут). В шахматном переборе, где будет относительно большая глубина рекурсии думать об оптимизациях надо, но очень осторожно.
Тут тоже есть несколько общих идей:
- библиотека дебютов (дебютная теория в шахматах очень продвинутая — Wiki + Database)
- библиотека эндшпилей (аналогично есть много баз данных с готовыми эндшпилями)
- итеративные углубления+кеширование: идея в том, чтоб делать перебор сначала на глубину 1, потом 2, 3 и так далее. При этом сохранять данную позицию, ее наилучший ход, глубину или еще что-то в какой-то хеш-таблице. Вся суть итеративных углублений в том, что результатом незаконченного перебора пользоваться нельзя (тогда лучше провести неполный перебор на меньшую глубину) и при переборе на большую глубину можно использовать результаты перебора на меньшую глубину. Даже выходит так, что перебор на глубину от 1 до 6 выполняется быстрее, чем перебор сразу на глубину 6.
В статье была использована информация с некоторых ресурсов:
- Rebel — Programmer Stuff — статья о программе Rebel (очень ценные идеи и решения)
- Поиск по шахматному дереву — общие идеи о программировании шахмат
- Форум о поисках алгоритма для шахмат одним человеком
- Сайт рабочей группы по искусственному интеллекту
- Как компьютеры играют в шахматы — статья на хабре
- Chess Program Sources — доступные исходники многих шахматных программ
P.S. Вся теория была мной использована на практике и некоторое время существовал несложный rest-вебсервис на PHP для шахмат онлайн + программа на C# (использовался .NET Remoting для сетевой игры), но теперь сайт не рабочий и когда будет время, хочу перенести на RubyOnRails.
P.P.S. Кому интересно — проект теперь живет на гуглокоде и апгрейдится, когда у меня есть время. Кто захочет код предыдущей версии — могу выслать.







