Хотя десять лет назад компания Intel прогнозировала процессоры 10 ГГц к 2011 году, реальность оказалась совершенно другой. Кто мог предположить, что главная вычислительная мощь будет уже не у CPU, а у графических процессоров. Вот как выглядит график роста количества операций с плавающей запятой (FLOPs) у CPU и GPU за последние десять лет.
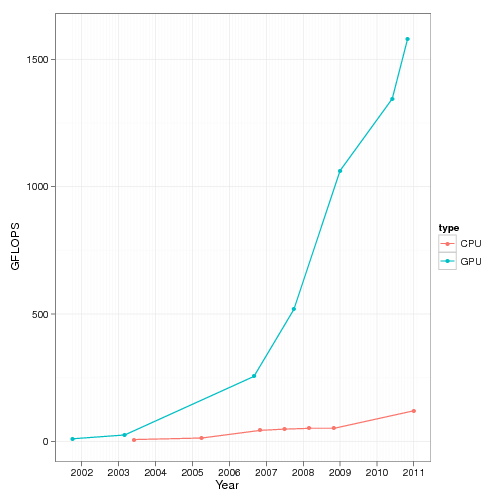
Тот же график на логарифмической шкале.
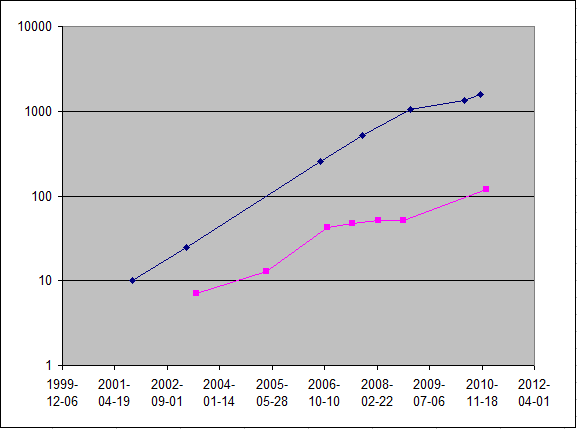
Понятно, что за счёт узкой специализации графический процессор может практически всю свою производительность отдавать на арифметические операции, тогда как архитектура CPU гораздо сложнее.
Тактовая частота процессоров Intel застыла в районе 3,4 ГГц.

Правда, общая производительность чипов продолжает расти за счёт увеличения числа ядер.

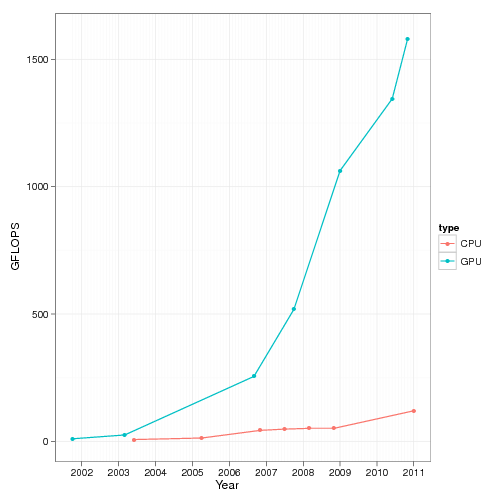
Тот же график на логарифмической шкале.
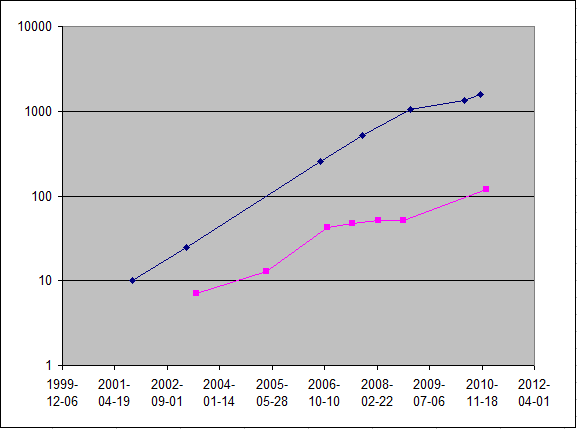
Понятно, что за счёт узкой специализации графический процессор может практически всю свою производительность отдавать на арифметические операции, тогда как архитектура CPU гораздо сложнее.
Тактовая частота процессоров Intel застыла в районе 3,4 ГГц.

Правда, общая производительность чипов продолжает расти за счёт увеличения числа ядер.









