
Функция распознавания речи с некоторого времени доступна в браузере Google Chrome. Посмотреть как это выглядит можно, например, здесь.
Так как исходный Chromium открыт, возникает закономерное желание подсмотреть, можно ли использовать технологию в
Как это часто бывает, все уже сделано за нас в этой статье. Все оказывается очень просто, необходимо сделать POST запрос на адрес www.google.com/speech-api/v1/recognize со звуковыми данными в формате FLAC или Speex. Реализуем демонстрацию распознавания WAVE-файлов с помощью C#.
Как и автор оригинального топика мы не будем связываться со Speex. Для конвертирования звука из формата Wave во FLAC я воспользовался библиотекой Cuetools . В ее коде почему-то выдавалось исключение при попытке сохранения FLAC с любым количеством каналов кроме двух, однако простым закомментированием этой проверки благополучно сохраняются моно-файлы, прекрасно понимаемые гуглом.
/// <summary> Конвертирование wav-файла во flac </summary>
/// <returns>Частота дискретизации</returns>
public static int Wav2Flac(String wavName, string flacName)
{
int sampleRate = 0;
IAudioSource audioSource = new WAVReader(wavName, null);
AudioBuffer buff = new AudioBuffer(audioSource, 0x10000);
FlakeWriter flakewriter = new FlakeWriter(flacName, audioSource.PCM);
sampleRate = audioSource.PCM.SampleRate;
FlakeWriter audioDest = flakewriter;
while (audioSource.Read(buff, -1) != 0)
{
audioDest.Write(buff);
}
audioDest.Close();
audioDest.Close();
return sampleRate;
}
Если у кого-то есть желание, думаю нет проблем реализовать без сохранения во временный FLAC-файл, не будем усложнять пример. Замечу только, что на файлы с высокой частотой дискретизации (44100) Гугл реагировал ошибкой 400. Максимально возможную частоту не определял, 8 и 16 кГц работает без проблем.
Основной метод запроса к Google Voice:
public static String GoogleSpeechRequest(String flacName, int sampleRate)
{
WebRequest request = WebRequest.Create("https://www.google.com/speech-api/v1/recognize?xjerr=1&client=chromium&lang=ru-RU");
request.Method = "POST";
byte[] byteArray = File.ReadAllBytes(flacName);
// Set the ContentType property of the WebRequest.
request.ContentType = "audio/x-flac; rate=" + sampleRate; //"16000";
request.ContentLength = byteArray.Length;
// Get the request stream.
Stream dataStream = request.GetRequestStream();
// Write the data to the request stream.
dataStream.Write(byteArray, 0, byteArray.Length);
dataStream.Close();
// Get the response.
WebResponse response = request.GetResponse();
dataStream = response.GetResponseStream();
// Open the stream using a StreamReader for easy access.
StreamReader reader = new StreamReader(dataStream);
// Read the content.
string responseFromServer = reader.ReadToEnd();
// Clean up the streams.
reader.Close();
dataStream.Close();
response.Close();
return responseFromServer;
}
Десериализацию JSON-ответа сделаем через DataContractJsonSerializer, здесь, признаюсь честно, я не силен, к тому же результаты от гугла всегда приходили в виде:
{"status":0,"id":"4531050901df65542082eacfebf3bb1b-1","hypotheses":[{"utterance":"купить велосипед","confidence":0.89697623}]}
Поэтому следующей простой десериализации вполне хватило, буду рад выслушать замечания.
[DataContract]
public class RecognizedItem
{
[DataMember]
public string utterance;
[DataMember]
public float confidence;
}
[DataContract]
public class RecognitionResult
{
[DataMember]
public string status;
[DataMember]
public string id;
[DataMember]
public RecognizedItem[] hypotheses;
}
public static RecognitionResult Parse(String toParse)
{
DataContractJsonSerializer ser = new DataContractJsonSerializer(typeof(RecognitionResult));
MemoryStream stream1 = new MemoryStream(ASCIIEncoding.UTF8.GetBytes(toParse));
RecognitionResult result= (RecognitionResult)ser.ReadObject(stream1);
return result;
}
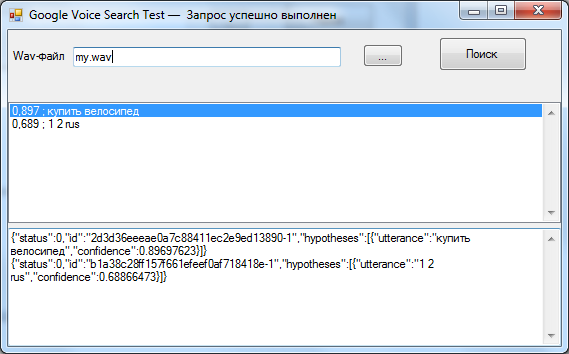
«Купить велосипед» на скриншоте распозналось абсолютно верно, «один два раз» распозналось как «1 2 rus». Скачать архив исходных кодов можно отсюда.
Наслаждаемся технологией, пока







