Предисловие
Как известно, задача распознавания непрерывного рукописного текста в режиме off-line пока считается нерешённой.
Мне удалось решить эту задачу теоретически и практически. Практическая часть сейчас имеет вид демонстрационной версии программы. Решение общее, оно не ограничивается какой-либо областью применения, языком или размером словаря.
О программе
Программа полностью обучаемая. Процесс обучения выглядит просто: вы пишете символы в режиме on-line, программа их обобщает и выделяет алгоритм написания. Это первый этап обучения. Второй этап происходит во время работы. Если встречается символ, общий алгоритм написания которого совпадает с одним из имеющихся в наличии, а значения некоторых свойств выходят за рамки вычисленных на первом этапе диапазонов, то диапазоны расширяются. Конечно, только после подтверждения пользователем общего результата распознавания. К слову сказать, на первом этапе достаточно от трёх до семи предъявлений символа, и алгоритм готов.
Теория
Немного о теории. Существует несколько подходов к решению указанной задачи. Их обычно делят на два вида: структурные и эталонные. Первый основан на выделении и анализе различных структурных элементов символа и их признаков, свойств. Второй предполагает сравнение распознаваемого символа с набором заданных эталонов. Эти методы не позволяют решить задачу в общем виде.
Задача рукописного ввода в режиме on-line полностью и успешно решена. Это решение основано, в любом случае, на создании алгоритмов написания символов, учитывающих траекторию движения пера. То есть, последовательность смены его координат. Были предложения свести задачу распознавания в off-line режиме к распознаванию в режиме on-line. Для этого достаточно правильно считать линии с графической копии текста. Но сделать это принципиально невозможно. Можно считать отрезки линий между пересечениями, но чтобы их правильно соединить, уже нужна интерпретация.
Остаётся только одно решение — восстанавливать символы в процессе интерпретации отрезков, полученных на этапе считывания с цифровой графической копии текста. Для этого нужны две составляющие: специальное представление алгоритма написания символа, позволяющее это делать, и алгоритм интерпретации отрезков, способный проанализировать все возможные варианты интерпретации.
Практика
Это удалось сделать в полной мере. Как известно, главная задача демоверсии — продемонстрировать принципиальное решение поставленной задачи. На что в этом смысле способен тот прототип, который имеется сейчас? Программа способна распознавать одно слово, написанное произвольным непрерывным почерком на белой бумаге. Для перевода в цифровой файл слово может быть либо отсканировано, либо сфотографировано веб-камерой или цифровым фотоаппаратом. В принципе, уже сделано и распознавание текста, но эта функция требует доработки.
Ниже приведены примеры распознаваемых слов. Как видно, здесь не только обычное написание, но и «усложнённые» варианты: перечёркнутые слова, символы, написанные отрезками, имеющие лишние части и тому подобное. Это показывает, что в полностью готовом виде программа будет способна распознавать достаточно зашумлённые тексты.
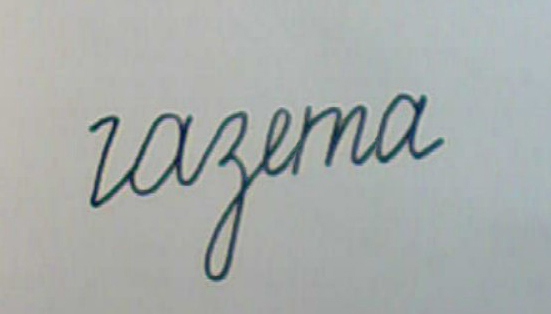
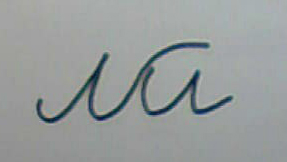
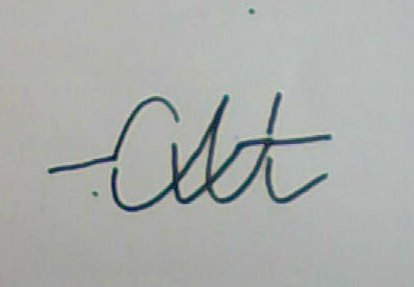

Очевидно, что уверенно распознать можно только те символы, которые имеют все необходимые части примерно на своих местах. Если имеются недостающие или сильно искажённые части, то необходима интерпретация на уровне слов. Наличие словаря повышает процент распознавания, но не решает всех проблем. Бывают такие случаи, когда без понимания смысла фразы некоторые слова однозначно интерпретировать невозможно. Для этого нужна система искусственного интеллекта, способная понимать смысл фраз естественного языка. До недавнего времени информации о наличии таких систем на рынке не было. Сейчас уже есть: фирма ABBYY объявила о создании системы «Compreno», в которой для перевода используется смысловая интерпретация фраз на основе «модели мира», не зависимой от конкретного языка.
У меня тоже есть прототип системы ИИ, способной понимать смысл текста. Если судить по той информации о «Compreno», которая сейчас есть в СМИ, моя система функционально гораздо шире. Она обучаема, способна к обобщению информации и к активному поиску знаний в случае, когда их не хватает для выполнения поставленной задачи. Другими словами, такая система вполне способна работать личным секретарём. Но у неё есть один серьёзный недостаток по сравнению с «Compreno» — по степени общей готовности она пока не дотягивает даже до демоверсии.
Коммерция
И в конце немного о коммерческой стороне проекта. В интернете есть интервью вице-президента компании ABBYY Lingvo Арама Пахчаняна. В отношении задачи распознавания непрерывного рукописного текста в режиме off-line там сказано, по сути, что эту задачу и не надо решать. Затраты на её решение (надо полагать, очень большие) не окупятся. И, похоже, в основном потому, что непрерывное писание фирма ABBYY Lingvo практически уже сделала неактуальным. Она полностью решила проблему распознавания раздельного рукописного текста, и на все случаи жизни разработала соответствующие бланки.
Возможно, это была шутка. Но всё равно, имеет смысл сказать следующее. Писать привычным непрерывным почерком удобнее и легче, чем вписывать буквы в квадратики. Если компьютер будет распознавать первое не хуже второго, то второе уйдёт в прошлое так же как перфокарты, чёрно-белые телевизоры и плёнки для фотоаппаратов.
В следующем короткое видео можно увидеть программу в действии. Возможно, это будет интересно.
Заключение
И ещё один важный момент – показатели эффективности, а именно, время и процент распознавания. Конечно, в демоверсии основное внимание уделялось второму критерию. Сейчас достигнут уровень не ниже 70%. В готовом варианте этот показатель можно сформулировать так: если человек сможет прочитать текст, то и программа тоже. О времени распознавания пока можно сказать только то, что его удастся довести до приемлемых величин.
Если всё пойдёт хорошо, будут ещё статьи о некоторых технических аспектах распознавания текста и об ИИ.
Благодарю за внимание.
____________
Update.
Дорогие хабравчане! Спасибо всем за фидбек, нам это очень важно и полезно. В целом топик был встречен положительно, что не может не радовать.
Негодующим личностям хотелось бы сказать: уважаемые, мы не ярмарочные фокусники. Мы отдаём отчёт в своих словах. Если мы написали, что в готовом продукте точность распознавания будет стремиться к 100%, значит мы в этом уверены.
Эту статью можете считать анонсом, у неё не было цели подробно раскрыть все технические подробности. Однако учитывая проявленный интерес, через некоторое время будет ещё одна статья, более подробно описывающая процесс распознавания.
Также будет доступная для скачивания демонстрационная версия программы.








