Последнее время многие пользователи стали замечать reCaptcha с кусками фотографий, содержащих номера домов, названия улиц и даже дорожные знаки.
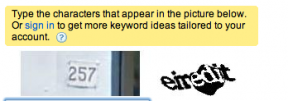
Представитель Google подтвердил, что они проводят экспериментынад людьми по улучшению качества своей БД информации об адресах и предприятиях с помощью распознавания фотографий Street View.
По результатам этихбесчеловечных опытов будет принято решение по использованию reCaptcha для других задач.
Небольшая коллекция таких капч, собранная пользователем форума blackhatworld.com:

(кликабельно)

Представитель Google подтвердил, что они проводят эксперименты
По результатам этих
Небольшая коллекция таких капч, собранная пользователем форума blackhatworld.com:

(кликабельно)







