В качестве эпиграфа:
Меня заинтересовал вопрос: а как именно происходит рост популярности талантливых «поэтов», которых все начинают читать в ситуации, когда каждый одновременно и «поэт» и читатель. Слово «поэт» я заключил в кавычки потому, что в реальности все описанное в эпиграфе напоминает нынешнюю блогосферу и социальные сети.
В этом посте будет много формул, графиков и всякой околонаучной болтологии. Я покажу пример моделирования небольшой социальной сети при помощи JavaScript используя методы Монте-Карло. На истину в последней инстанции я не претендую. Однако, вполне вероятно, этот пост окажется полезным для тех, кто захочет сделать сам нечто подобное.
Итак, для начала распишем особенности нашей сильно упрощенной виртуальной «блогосферы».
1. Есть N штук участников, каждый из них характеризуется номером i=1...N.
2. Каждый из них читает K штук других участников (френды). Все это задается двумерным массивом:
Pi,k содержит номер k-того френда i-того участника.
3. Для каждого участника случайным образом выбираются Hat штук (для всех одинаково) «врагов» — номера тех участников, которых данный участник никогда сам не зафрендит.
4. У каждого участника i есть личное свойство — мера таланта. Хранится в массиве Ti.
5. Величина Ti случайным образом раздается каждому участнику в самом начале.
6. Также в начале каждый участник получает K штук случайных френдов.
7. При этом, число читателей каждого Ri уже получается случайным, хоть примерно близким к значению K (если каждый читает K случайных человек, то и его самого будут читать примерно столько же).
8. Задается число Days дней эксперимента.
9. Задаются положительные числа q и r: q характеризует то, насколько для участников важно качество постов, а r характеризует то, насколько важна уже имеющаяся популярность при принятии решения о френдинге.
Под днем я понимаю одну итерацию главного цикла. Что происходит в этом цикле.
1. Каждый i участник пишет 1 пост качества Qi. Значение Qi — случайная величина, однако, ее распределение зависит от таланта Ti. Чем больше значение Ti, тем более вероятно увидеть от участника i посты с высоким качеством Qi.
2. У каждого участника i выбирается один френд, качество трех последних постов которого ниже, чем у остальных френдов. Этого френда будем заменять на нового.
3. Кандидатуру на замену ищем среди френдов френдов, отсеивая среди них тех, кто уже является френдом или врагом.
4. Каждому из списка претендентов на замену мы присваиваем число, характеризующее вероятность, с которой мы выберем именно его. Эта вероятность зависит от качества его трех последних постов Qi и уже имеющейся популярности Ri. Вероятность в моей модели описывается простой формулой:

Как видно, чем лучше у кандидата посты и чем он популярнее, тем больше будет вероятность выбрать именно его. Константа C, одинаковая для всех претендентов, служит для нормировки, так чтобы сумма всех вероятностей для всех кандидатов была равна единице.
5. Случайным образом, но с учетом не равных вероятностей выбираем замену из подготовленного списка и заменяем старого френда на нового. И так проделываем с каждым из N.
Главный показатель, который интересен в этом исследовании — число читателей Ri, как оно меняется с каждым днем. А конкретно — у первых трех участников с самым большим талантом.
6. После всех замен рассчитаем значение дисперсии D распределения Ri. Число D характеризует среднеквадратичное отклонение от среднего числа читателей. Для примера, если у каждого из N одинаковое число читателей, то среднее как раз и равно этому числу, а отклонения от среднего — нет (все одинаковы!), тогда и дисперсия равна нулю. А вот чем больше неравенство в числе читателей, тем больше будет и дисперсия D. Вот выражение для нее:

где угловыми скобками обозначено усреднение по всем участникам:

7. Необходимая статистика записывается в массивы для дальнейшего вывода на графики и цикл повторяется снова, пока не пройдут Days дней.
Также в рамках моделирования проводится такой эксперимент. Один из рядовых участников (Rabbit) в день DayX вдруг волшебным образом получает талант такой же по величине, как и самый талантливый участник + одного читателя. Как при этом он будет карабкаться к вершине славы, учитывая то, что ко времени DayX таланты уже вероятно получили свой максимум читателей? За его успехами также ведется наблюдение.
Углубляясь в детали. Одной из задач методов Монте-Карло является генерирование случайных чисел с заданным распределением.

То есть нужно из стандартной машинной функции random() с равномерным распределением (рисунок выше) сделать свое, особое:

Напомню, что значение f(x)dx по определению равно вероятности выпадения числа, лежащего в промежутке от x до x+dx. Поэтому, само собой, интеграл от f(x) должен быть равен 1.
Для некоторых, особых видов f(x) задача решается аналитически. Так, для генерирования случайных талантов T я использовал затухающую экспоненту:

Точно такую же экспоненту я использовал и для дальнейшего генерирования случайного качества Q постов участника с заданным талантом T:
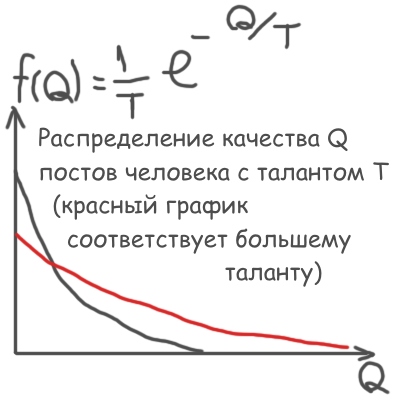
Так вот, как генерировать Q, распределенное по закону f(x), что на рисунке выше, используя при этом равномерно распределенное от 0 до 1 случайное число Rnd? Очень просто:
 .
.
Теперь, о том, какая может быть максимальная дисперсия и зачем введены «враги».
В первом варианте, без антипатии, ситуация развивалась просто: список из K френдов у всех N участников был одинаковым и содержал первые K самых талантливых. Ну и еще K+1 имел читателей за счет тех K первых. Эта ситуация соответствует максимальному значению дисперсии D, которое примерно равно (при условии 1<<K<<N):
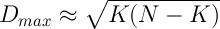 .
.
Чем большее количество «врагов» мы вводим, тем меньшей получается итоговая дисперсия. Итак, вот результаты симуляции:
В случае, если люди больше ценят популярность, чем качество постов:

В большинстве случаев набор популярности идет медленно. Наблюдаются временные провалы популярности (вот возможный ответ тем, кто регулярно создает посты в ЖЖ о том, что вот гады, опять социальный капитал (СК) срубили!). Это связано с особенностью выбранной функции распределения, когда при любом таланте большинство постов имеют свойство быть близкими к нулю.
Случай, если люди одинаково оценивают популярность и качество постов:
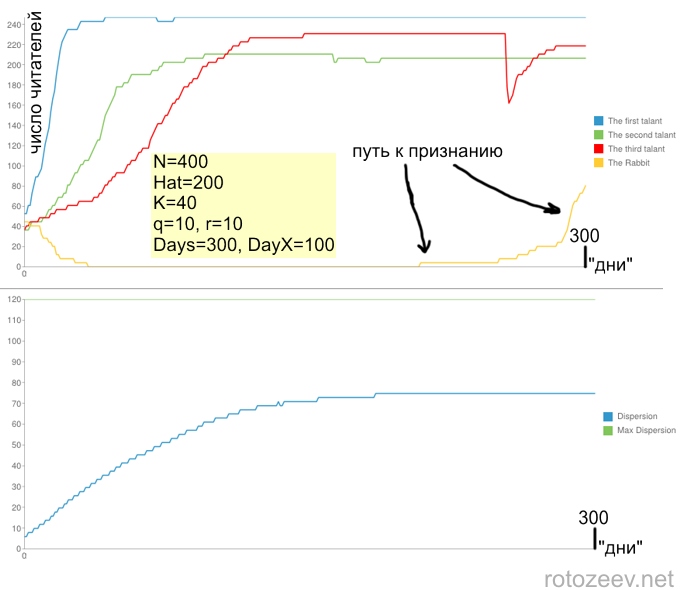
Хочется отметить, что разные реализации алгоритма с одинаковыми параметрами могут приводить к очень разнообразным зависимостям числа читателей от времени. Общие черты есть, но очень расплывчатые. Однако, зависимость дисперсии, как интегральной, усредненной величины практически неизменна при одинаковых параметрах. В зависимости дисперсии от времени важны два параметра: время выхода на асимптотику, то есть время за которое блогосфера приходит в равновесное состояние, после которого перестают происходить массовые перетоки читателей, а также сама асимптотика, которая определяется соотношением между N и Hat.
Алгоритм был реализован на JavaScript, графики рисовались при помощи Chart Google API, так что любой пользователь современного компьютера может легко воспроизвести эти результаты, а то и улучшить их реализацию.
Небольшой приятный (потому что легкий) вопрос на будущее: насколько точно получится считать дисперсию распределения Ri, если усреднять не по всему набору N, а по меньшему числу n<<N случайно выбранных участников? Ведь если окажется, что небольшая случайная выборка хорошо отображает всю популяцию блоггеров, то можно, например, следить за «погодой» в том же ЖЖ — высчитывая каждый день дисперсию и оценивая ее тенденции.
— У них там очень много поэтов. Все пишут стихи, и каждый поэт,
естественно, хочет иметь своего читателя. Читатель же — существо
неорганизованное, он этой простой вещи не понимает. Он с удовольствием
читает хорошие стихи и даже заучивает их наизусть, а плохие знать не
желает. Создается ситуация несправедливости, неравенства, а поскольку
жители там очень деликатны и стремятся, чтобы всем было хорошо, создана
специальная профессия — читатель. Одни специализируются по ямбу, другие — по хорею, а Константин Константинович — крупный специалист по амфибрахию и
осваивает сейчас александрийский стих, приобретает вторую специальность.
Цех этот, естественно, вредный, и читателям полагается не только усиленное
питание, но и частые краткосрочные отпуска.
Стругацкие, Сказка о Тройке
Меня заинтересовал вопрос: а как именно происходит рост популярности талантливых «поэтов», которых все начинают читать в ситуации, когда каждый одновременно и «поэт» и читатель. Слово «поэт» я заключил в кавычки потому, что в реальности все описанное в эпиграфе напоминает нынешнюю блогосферу и социальные сети.
В этом посте будет много формул, графиков и всякой околонаучной болтологии. Я покажу пример моделирования небольшой социальной сети при помощи JavaScript используя методы Монте-Карло. На истину в последней инстанции я не претендую. Однако, вполне вероятно, этот пост окажется полезным для тех, кто захочет сделать сам нечто подобное.
Итак, для начала распишем особенности нашей сильно упрощенной виртуальной «блогосферы».
1. Есть N штук участников, каждый из них характеризуется номером i=1...N.
2. Каждый из них читает K штук других участников (френды). Все это задается двумерным массивом:
Pi,k содержит номер k-того френда i-того участника.
3. Для каждого участника случайным образом выбираются Hat штук (для всех одинаково) «врагов» — номера тех участников, которых данный участник никогда сам не зафрендит.
4. У каждого участника i есть личное свойство — мера таланта. Хранится в массиве Ti.
5. Величина Ti случайным образом раздается каждому участнику в самом начале.
6. Также в начале каждый участник получает K штук случайных френдов.
7. При этом, число читателей каждого Ri уже получается случайным, хоть примерно близким к значению K (если каждый читает K случайных человек, то и его самого будут читать примерно столько же).
8. Задается число Days дней эксперимента.
9. Задаются положительные числа q и r: q характеризует то, насколько для участников важно качество постов, а r характеризует то, насколько важна уже имеющаяся популярность при принятии решения о френдинге.
Под днем я понимаю одну итерацию главного цикла. Что происходит в этом цикле.
1. Каждый i участник пишет 1 пост качества Qi. Значение Qi — случайная величина, однако, ее распределение зависит от таланта Ti. Чем больше значение Ti, тем более вероятно увидеть от участника i посты с высоким качеством Qi.
2. У каждого участника i выбирается один френд, качество трех последних постов которого ниже, чем у остальных френдов. Этого френда будем заменять на нового.
3. Кандидатуру на замену ищем среди френдов френдов, отсеивая среди них тех, кто уже является френдом или врагом.
4. Каждому из списка претендентов на замену мы присваиваем число, характеризующее вероятность, с которой мы выберем именно его. Эта вероятность зависит от качества его трех последних постов Qi и уже имеющейся популярности Ri. Вероятность в моей модели описывается простой формулой:
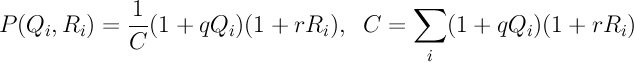
Как видно, чем лучше у кандидата посты и чем он популярнее, тем больше будет вероятность выбрать именно его. Константа C, одинаковая для всех претендентов, служит для нормировки, так чтобы сумма всех вероятностей для всех кандидатов была равна единице.
5. Случайным образом, но с учетом не равных вероятностей выбираем замену из подготовленного списка и заменяем старого френда на нового. И так проделываем с каждым из N.
Главный показатель, который интересен в этом исследовании — число читателей Ri, как оно меняется с каждым днем. А конкретно — у первых трех участников с самым большим талантом.
6. После всех замен рассчитаем значение дисперсии D распределения Ri. Число D характеризует среднеквадратичное отклонение от среднего числа читателей. Для примера, если у каждого из N одинаковое число читателей, то среднее как раз и равно этому числу, а отклонения от среднего — нет (все одинаковы!), тогда и дисперсия равна нулю. А вот чем больше неравенство в числе читателей, тем больше будет и дисперсия D. Вот выражение для нее:
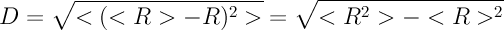
где угловыми скобками обозначено усреднение по всем участникам:
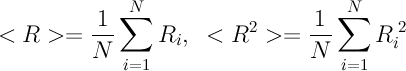
7. Необходимая статистика записывается в массивы для дальнейшего вывода на графики и цикл повторяется снова, пока не пройдут Days дней.
Также в рамках моделирования проводится такой эксперимент. Один из рядовых участников (Rabbit) в день DayX вдруг волшебным образом получает талант такой же по величине, как и самый талантливый участник + одного читателя. Как при этом он будет карабкаться к вершине славы, учитывая то, что ко времени DayX таланты уже вероятно получили свой максимум читателей? За его успехами также ведется наблюдение.
Углубляясь в детали. Одной из задач методов Монте-Карло является генерирование случайных чисел с заданным распределением.
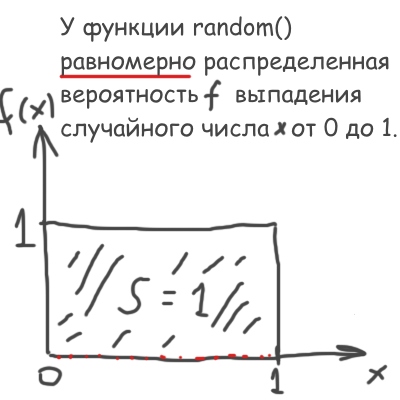
То есть нужно из стандартной машинной функции random() с равномерным распределением (рисунок выше) сделать свое, особое:
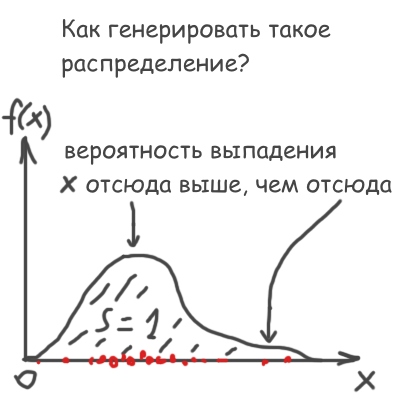
Напомню, что значение f(x)dx по определению равно вероятности выпадения числа, лежащего в промежутке от x до x+dx. Поэтому, само собой, интеграл от f(x) должен быть равен 1.
Для некоторых, особых видов f(x) задача решается аналитически. Так, для генерирования случайных талантов T я использовал затухающую экспоненту:
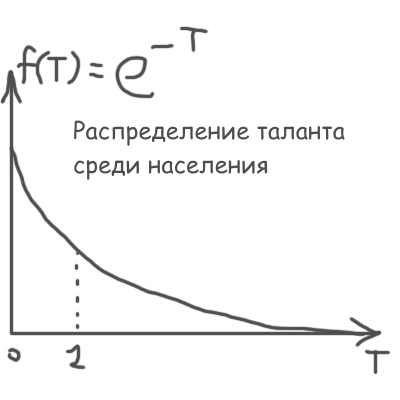
Точно такую же экспоненту я использовал и для дальнейшего генерирования случайного качества Q постов участника с заданным талантом T:

Так вот, как генерировать Q, распределенное по закону f(x), что на рисунке выше, используя при этом равномерно распределенное от 0 до 1 случайное число Rnd? Очень просто:
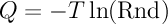 .
.Теперь, о том, какая может быть максимальная дисперсия и зачем введены «враги».
В первом варианте, без антипатии, ситуация развивалась просто: список из K френдов у всех N участников был одинаковым и содержал первые K самых талантливых. Ну и еще K+1 имел читателей за счет тех K первых. Эта ситуация соответствует максимальному значению дисперсии D, которое примерно равно (при условии 1<<K<<N):
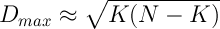 .
.Чем большее количество «врагов» мы вводим, тем меньшей получается итоговая дисперсия. Итак, вот результаты симуляции:
В случае, если люди больше ценят популярность, чем качество постов:
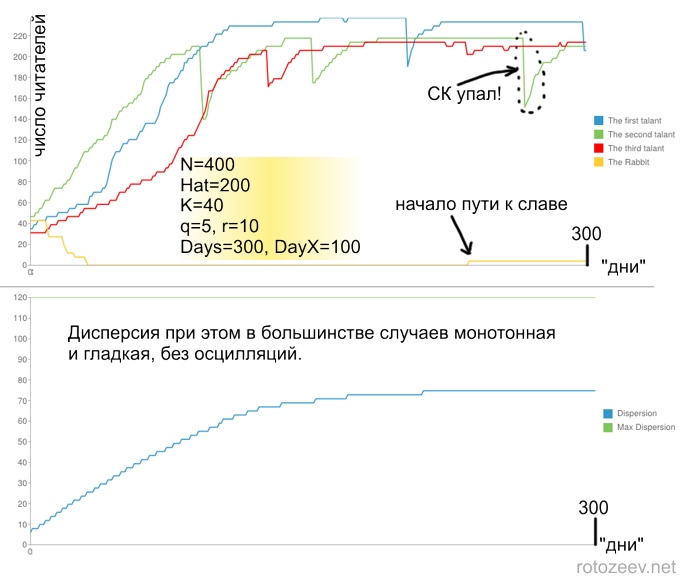
В большинстве случаев набор популярности идет медленно. Наблюдаются временные провалы популярности (вот возможный ответ тем, кто регулярно создает посты в ЖЖ о том, что вот гады, опять социальный капитал (СК) срубили!). Это связано с особенностью выбранной функции распределения, когда при любом таланте большинство постов имеют свойство быть близкими к нулю.
Случай, если люди одинаково оценивают популярность и качество постов:
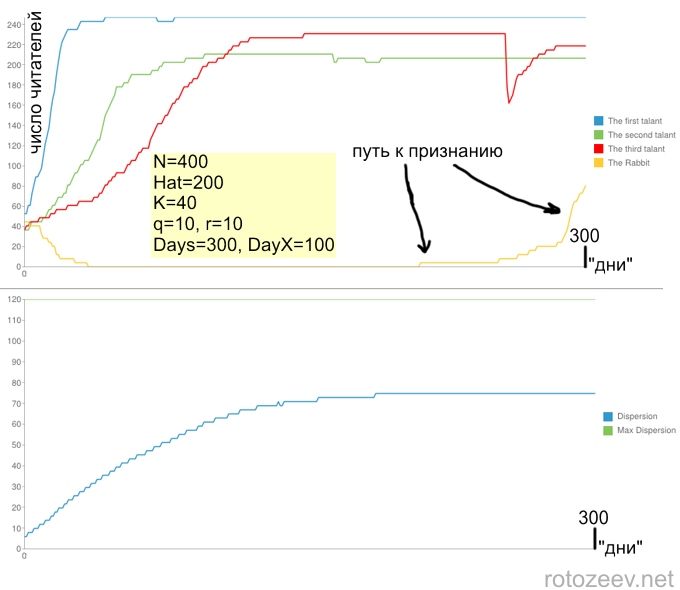
Хочется отметить, что разные реализации алгоритма с одинаковыми параметрами могут приводить к очень разнообразным зависимостям числа читателей от времени. Общие черты есть, но очень расплывчатые. Однако, зависимость дисперсии, как интегральной, усредненной величины практически неизменна при одинаковых параметрах. В зависимости дисперсии от времени важны два параметра: время выхода на асимптотику, то есть время за которое блогосфера приходит в равновесное состояние, после которого перестают происходить массовые перетоки читателей, а также сама асимптотика, которая определяется соотношением между N и Hat.
Алгоритм был реализован на JavaScript, графики рисовались при помощи Chart Google API, так что любой пользователь современного компьютера может легко воспроизвести эти результаты, а то и улучшить их реализацию.
Небольшой приятный (потому что легкий) вопрос на будущее: насколько точно получится считать дисперсию распределения Ri, если усреднять не по всему набору N, а по меньшему числу n<<N случайно выбранных участников? Ведь если окажется, что небольшая случайная выборка хорошо отображает всю популяцию блоггеров, то можно, например, следить за «погодой» в том же ЖЖ — высчитывая каждый день дисперсию и оценивая ее тенденции.




