Facebook разработал алгоритм под названием DeepFace, который позволяет идентифицировать лицо в толпе с точностью 97,25 %, что почти соответствует способностям среднего человека (97,53 %), пишет TechCrunch.
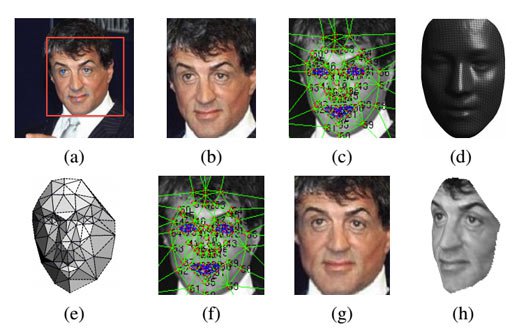
Чтобы преодолеть ограничения обычных программ для распознавания лиц разработчики Facebook нашли способ строить 3D-модели лица по фотографии. Эти модели затем можно вращать, чтобы обеспечить распознавание одного лица, запечатлённого под разными углами. В прошлом же попытка распознания лица легко могла стать неудачной, если человек просто немного наклонил голову в другую сторону.
Для полноценной работы алгоритма DeepFace его нужно обучить на большом числе лиц. В текущей версии он может идентифицировать до 4 тысяч людей на основе базы данных из более 4 миллионов отдельных изображений. Теоретически эту базу можно расширить для того, чтобы применить к самой социальной сети Facebook, что было бы полезно, если Facebook захочет автоматизировать процесс идентификации всех ваших контактов и распознавать лица на фотографиях без необходимости ручной отметки пользователями.
Пока что этот проект оформлен только в виде исследовательской работы, опубликованной на прошлой неделе, и группа авторов собирается представить результаты работы на конференции Computer Vision and Pattern Recognition в Колумбусе, штат Огайо, в июне. Тем не менее, проект имеет огромный потенциал для будущего применения, как в самом Facebook, так и в области искусственного интеллекта.







