Время идёт, и мультиклеточный процессор продолжает расти, развиваться. Пока, правда, не размножается, и состоит всего из 4-х клеток, но это все у него впереди. В данной статье попытаюсь описать основные особенности нового процессора Мультиклет R1, его характеристики и функционал, а также сравнить процессор нового поколения с родоначальником династии — процессором Мультиклет P1.
Кратко пробежимся по историческим моментам выпуска процессоров, заглянем ненадолго в теоретические основы работы наших процессоров, обратим внимание на особенности нового процессора и его основные возможности, сравним процессоры P1 и R1, покажем прототип первого продукта на R1, и в завершении сделаем небольшой анонс.

Рис 1. Кремниевая пластина процессоров R1
1. История создания
Компания Мультиклет была основана в 2010 году. С учетом наработок по проекту синпьютер Уральской архитектурной лаборатории, которые велись с 2001 года под руководством Н.В.Стрельцова, был сделан шаг по созданию первого процессора с новой российской архитектурой. И все усилия вылились в первого представителя универсальной мультиклеточной архитектуры – процессор Мультиклет P1. Буква “P” означает нацеленный на производительность (Performance). После выпуска процессора были изготовлены две версии отладочных комплектов, а затем — несколько серийных устройств, в том числе фольгиратор, устройство защиты информации Key_P1. Имела место активная работа пользователей, тех, кому было интересно попробовать что-то новое. Результатом этой деятельности явились примеры работы с тачскрином, управление асинхронными двигателями, высотомер, анализатор трехосевого датчика и другое.
Но, несомненно, было необходимым подняться на новую ступень. И в 2014 году появился на свет процессор с динамической реконфигурацией под названием R1-1. По результатам испытаний данная ревизия ушла в опытные образцы, и следом в декабре 2014 был выпущен процессор R1, доступный в пластиковом корпусе с марта 2015 г. Именно об этом процессоре и пойдет речь в данной статье.
Добавлю, что мультиклеточные процессоры разрабатываются в г. Екатеринбург, кристалл выпекается в Малайзии на фабрике SilTerra.

Рис 2. Процессор R1
2. Краткие основы архитектуры
Процессор R1, как и первый представитель мультиклеточной архитектуры, состоит из четырех клеток. В архитектуру заложены следующие основные принципы:
Рассмотрим состав процессорного блока – клетки. Клетка процессора R1 в своем составе имеет блок выборки и распределения команд (IDU), блок управления и декодер команд (CU), буферное устройство (BUF), коммутационное устройство (SU), мультиплексор результатов, контроллер прерываний (IC), отладочный блок (JTAG-GPR), блок регистров общего назначения (GPR), исполнительное устройство (EU), состоящее из арифметико-логического устройства (далее АЛУ) с плавающей запятой двойной точности (ALU_FLOAT), АЛУ для целых чисел (ALU_INTEGER) и блок доступа к памяти данных (DMS).
Связующим элементом клеток является межклеточная среда, которая представляет собой провода, соединяющие коммутационные устройства клеток и их входы, выходы. Хранилищем результатов является коммутатор (SU), который хранит информацию, приходящую из «межклеточной среды».
Основными преимуществами архитектуры является низкое энергопотребление, достижение при этом максимальной производительности, и динамическое распределение ресурсов.
Низкое энергопотребление достигается за счет простоты реализации данной архитектуры, использования принципа широковещательно рассылки, отсутствия сложных блоков предсказателей переходов, кэша, переупорядочения инструкций и т.п.
Высокая производительность достигается за счет того, что «на прямых» мультиклеточная архитектура быстрее, а на «поворотах» не хуже существующих архитектур.
Вся программа представляет собой набор инструкций, объединенных в параграфы.
Параграф мультиклеточной архитектуры можно представить как большую команду для обычной процессорной архитектуры. Параграф подразумевается под «прямой», а переходы между параграфами являются «поворотами».

Рис 3. Иллюстрация поворота
Если кратко охватить преимущества архитектуры, то с небольшими коррекциями процитирую пользователя AlexDi с форума ixbt:
«Внеочередное выполнение до 4-х произвольных команд за такт, с глубиной внеочередности до 64 команд, предвычисление перехода задолго до самого перехода, преддекодинг команд после точки перехода, сохранение арифметических флагов для результатов всех инструкций».
В каждом такте на исполнение могут отправиться до 12-ти команд (4 клетки с тремя независимыми портами для ALU_FLOAT, ALU_INTEGER, DMS в каждой), но выход у них один, поэтому выдать результат в текущей реализации архитектуры могут до 4-х команд за такт. Производительность в Гигафлопсах получается в пике за счет темпа выполнения команд комплексного умножения двух аргументов (a + bi) * (c+di), в результате получаем 6 операций на клетку, умножаем на 4 клетки и получаем 24 операции за такт. Умножив количество операций за такт на частоту (для R1 это 100 МГц) получим 2,4 ГФлопса.
Подробнее ознакомиться с архитектурой можно в статье «Мультиклеточный процессор — это что?»
3. Что нового в процессоре R1
Первоначально предполагалось немножко доработать процессор P1, но в процессе доработки у R1 получилось практически полностью новое ядро. Теперь память программ общая для всех клеток, соответственно изменился механизм выборки (в P1 у каждой клетке была своя память программ), изменился механизм распределения результатов. Появилась косвенная адресация, добавились команды прямого чтения и записи (минуя механизм очередности), улучшена работа с индексными регистрами. И самое главное, появилась реконфигурация (способность клеток объединяться в группы).
Увеличился ассортимент команд ассемблера, появился блок работы с памятью DTC. Для тактирования достаточно кварца на 8-12 МГц, появилась возможность работать с внешней памятью типа SRAM, SDRAM, PROM, I/O. USB теперь стандарта 2.0 device, RTC с календарем на борту. И важным шагом стала работа аналоговых блок, в процессоре R1 содержится 8 независимых каналов дельта-сигма АЦП 16 бит, 48 киловыборок в секунду и 1 канал ЦАП до 100 мегавыборок в секунду(работает на системной частоте). Первоначально планировалось, что будет два канала ЦАП, но получился один полностью работающий канал ЦАП.
Рассмотрим чуть подробнее несколько нововведений в процессоре R1. Но для начала напомню как выглядит пример параграфа на ассемблере (для P1 и R1 можно писать и на Си):
Косвенная адресация
Введение косвенной адресации позволяет взять значение из памяти по выражению, записанному в качестве второго аргумента функции. Данный тип адресации позволяет повысить быстродействие и упростить код программы.
Рассмотрим простой пример:
В параграфе с косвенной адресацией сначала будет получено значение #0 равное 0x10, затем по данному адресу будет считано значение из памяти равное 0x50 и после этого выполнится чтение rdl по адресу 0x50, результатом которого будет число 0x12345. Без применения косвенной адресации в данном случае потребуется две команды.
В качестве значения в квадратных скобках результат выполнения какой-либо команды, выражение в виде суммы с константой, системный регистр, регистр общего назначения или индексный регистр.
Дополнительные команды
Система команд значительно расширилась в новой версии процессора, появились команды подсчета единиц, копирования флагов, различных сравнений и многое др. Продемонстрируем работу новых команд ge и lt для перехода по различным отрезкам.
Кратко поясним функции команд:
1) синтаксис: ge ARG1, ARG2 — проверка условия «больше или равно»
результат: «1» если ARG1 >= ARG2, иначе 0
2) синтаксис: lt ARG1, ARG2 — проверка условия «меньше»
результат: «1» если ARG1 < ARG2, иначе 0
Пусть у нас есть участки от 0 до 3, от 4 до 10, от 11 и более. При значениях переменной Х необходимо осуществить переход на соответствующий параграф, покажем на примере:
Хотелось ещё показать пример работы даже не команды, а нового регистра DFADDR, который можем быть полезен, например, для оптимизации конструкции в Си switch-case. Пример кода на Си и аналогичного параграфа:
4. Сравним процессоры P1 и R1
Сравнение начнем с тактирования. Для процессора P1 был необходим генератор тактовой частоты на 80, 100 или 120 МГц. В R1 появился блок PLL и теперь достаточно кварца на 8-12 МГц.
Для работы программы в P1 нужна внешняя флешка, из которой программа перекачивается в оперативную память процессора. В R1 программа может быть также загружена из флешки, а благодаря появившемуся контроллеру внешней памяти возможно выполнение и работа с SRAM, SDRAM памятью и другими по интерфейсу I/O. Кроме того процессор R1 может быть закорпусирован со встроенной флешкой на борту.
Поскольку появился блок управления внешней памятью, то появилась необходимость в перекладывании данных, этим в R1 занимается блок DTC, который способен работать и с регистрами и по прерываниям и с периферией. В R1, в отличие от P1, работают все прерывания.
Количество памяти в R1 возросло до 512 Кбайт с полным доступом к памяти данных и программ и выполнением команд из любой области памяти. В P1 было 128 Кбайт памяти программ, доступа к которой на чтение и запись у пользователя не было и 128 Кбайт памяти данных.
По периферийным блокам подробная информация была приведена выше. Добавлю, что теперь операции с плавающей запятой в R1 двойной точности.
И самое главное, что появилось в R1 – это реконфигурация, т.е. способность клеток объединяться в группы без перезагрузки процессора и перераспределяться. Например, две клетки могут заниматься вычислением, одна клетка периферией и передачей информации, оставшаяся клетка анализом датчиков и если потребуется, то во время работы процессора «прямо на лету» возможно сделать так, чтобы 3 клетки стали заниматься вычислениями, а одна опросом датчиков и периферией. По реконфигурации будет отдельная статья с примерами, пока лишь скажу, что работать с реконфигурацией очень просто, на Си это будет просто вызов одной функции типа fork() с указанием сколько клеток от основного потока мы отделяем и куда, на ассемблере также просто, приведу пример ассемблерной вставки для выполнения трех независимых программ на Си:
Допустим у нас есть 3 программы на Си, в которых мы указываем вместо main():
main1(), main2(), main3(), далее сделаем следующую ассемблерную вставку:
Приведём сравнительную таблицу основных параметров P1 и R1:
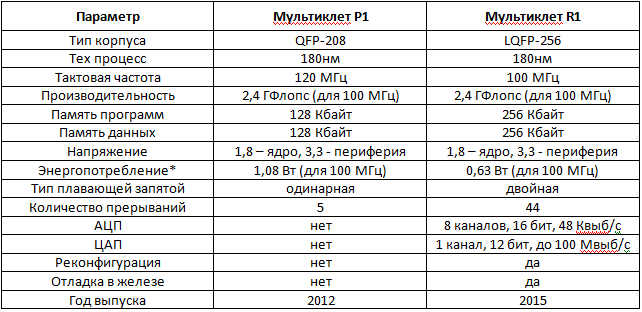
*Энергопотребление приведено на смеси задач 75% DMAC + 25% ADD. Максимальное потребление для R1 на задаче FFT составит 1,05 Вт. Энергопотребление P1 не имеет больших изменений в зависимости от задачи.
В R1 уже реализован для некоторых блоков clock gating для снижения энергопотребления, при этом количество транзисторов в R1 в 1,5 раза больше чем в P1.
Для каждого процессора имеется возможность писать программы на ассемблере, Си, отлаживать их и выполнять на процессоре. В качестве среды разработки выбран простой редактор Geany.
Работать в среде можно под Windows и Linux. Обзор среды разработки и средств также будет выделен в отдельную статью.
5. Анонс
Хочется поделиться тем, что процессор R1 работает, как и планировали, отладочные платы под него откорретированы и уже мы сами сделали прототип защищенного криптотелефона с использованием реконфигурации и встроенных АЦП, ЦАП. Примерный вид корпуса изображен на рисунке 4. Работающий макет на рисунке 5.

Рис 4. Прототип корпуса телефона

Рис 5. Работающий макет криптотелефона
Сейчас у нас идёт активная фаза по внедрению наших процессоров в школы (в виде робототехнических занятий) и Вузы в виде создания лабораторий, поэтому важным шагом мы считаем снижение порога вхождения в работу с новыми мультиклеточными процессорами.
Для этого мы планируем сделать цикл обучающих статей на портале Хабрахабр, краткий анонс и очередность статей приведу ниже с целью получить отклик в плане порядка выпуска лекций и содержания:
Спасибо всем кто дочитал до конца, буду рад конструктивной критике и комментариям.
Поздравляю всех пользователей портала Хабрахабр с днем радио!
Кратко пробежимся по историческим моментам выпуска процессоров, заглянем ненадолго в теоретические основы работы наших процессоров, обратим внимание на особенности нового процессора и его основные возможности, сравним процессоры P1 и R1, покажем прототип первого продукта на R1, и в завершении сделаем небольшой анонс.

Рис 1. Кремниевая пластина процессоров R1
1. История создания
Компания Мультиклет была основана в 2010 году. С учетом наработок по проекту синпьютер Уральской архитектурной лаборатории, которые велись с 2001 года под руководством Н.В.Стрельцова, был сделан шаг по созданию первого процессора с новой российской архитектурой. И все усилия вылились в первого представителя универсальной мультиклеточной архитектуры – процессор Мультиклет P1. Буква “P” означает нацеленный на производительность (Performance). После выпуска процессора были изготовлены две версии отладочных комплектов, а затем — несколько серийных устройств, в том числе фольгиратор, устройство защиты информации Key_P1. Имела место активная работа пользователей, тех, кому было интересно попробовать что-то новое. Результатом этой деятельности явились примеры работы с тачскрином, управление асинхронными двигателями, высотомер, анализатор трехосевого датчика и другое.
Но, несомненно, было необходимым подняться на новую ступень. И в 2014 году появился на свет процессор с динамической реконфигурацией под названием R1-1. По результатам испытаний данная ревизия ушла в опытные образцы, и следом в декабре 2014 был выпущен процессор R1, доступный в пластиковом корпусе с марта 2015 г. Именно об этом процессоре и пойдет речь в данной статье.
Добавлю, что мультиклеточные процессоры разрабатываются в г. Екатеринбург, кристалл выпекается в Малайзии на фабрике SilTerra.

Рис 2. Процессор R1
2. Краткие основы архитектуры
Процессор R1, как и первый представитель мультиклеточной архитектуры, состоит из четырех клеток. В архитектуру заложены следующие основные принципы:
- клетки независимы и идентичны
- никто и ничто не управляет клетками, нет центрального блока управления
- клетки могут быть объединены в любую конфигурацию в любом количестве
- прямая связность инструкций по данным (в качестве аргумента инструкции напрямую указывается инструкция, результат которой нам необходим)
- одна и та же программа может быть выполнена на любом количестве клеток
- работаем тогда, когда есть работа (т.е. когда данных нет, инструкции, от них зависящие, не выполняются)
- все команды готовые к выполнению, выполняются одновременно (в каждом такте могут быть выполнены по 1 команде из каждого блока ALU_INTEGER, ALU_FLOAT, DMS и так в каждой клетке)
- динамическое распределение ресурсов
Рассмотрим состав процессорного блока – клетки. Клетка процессора R1 в своем составе имеет блок выборки и распределения команд (IDU), блок управления и декодер команд (CU), буферное устройство (BUF), коммутационное устройство (SU), мультиплексор результатов, контроллер прерываний (IC), отладочный блок (JTAG-GPR), блок регистров общего назначения (GPR), исполнительное устройство (EU), состоящее из арифметико-логического устройства (далее АЛУ) с плавающей запятой двойной точности (ALU_FLOAT), АЛУ для целых чисел (ALU_INTEGER) и блок доступа к памяти данных (DMS).
Связующим элементом клеток является межклеточная среда, которая представляет собой провода, соединяющие коммутационные устройства клеток и их входы, выходы. Хранилищем результатов является коммутатор (SU), который хранит информацию, приходящую из «межклеточной среды».
Основными преимуществами архитектуры является низкое энергопотребление, достижение при этом максимальной производительности, и динамическое распределение ресурсов.
Низкое энергопотребление достигается за счет простоты реализации данной архитектуры, использования принципа широковещательно рассылки, отсутствия сложных блоков предсказателей переходов, кэша, переупорядочения инструкций и т.п.
Высокая производительность достигается за счет того, что «на прямых» мультиклеточная архитектура быстрее, а на «поворотах» не хуже существующих архитектур.
Вся программа представляет собой набор инструкций, объединенных в параграфы.
Параграф мультиклеточной архитектуры можно представить как большую команду для обычной процессорной архитектуры. Параграф подразумевается под «прямой», а переходы между параграфами являются «поворотами».

Рис 3. Иллюстрация поворота
Если кратко охватить преимущества архитектуры, то с небольшими коррекциями процитирую пользователя AlexDi с форума ixbt:
«Внеочередное выполнение до 4-х произвольных команд за такт, с глубиной внеочередности до 64 команд, предвычисление перехода задолго до самого перехода, преддекодинг команд после точки перехода, сохранение арифметических флагов для результатов всех инструкций».
В каждом такте на исполнение могут отправиться до 12-ти команд (4 клетки с тремя независимыми портами для ALU_FLOAT, ALU_INTEGER, DMS в каждой), но выход у них один, поэтому выдать результат в текущей реализации архитектуры могут до 4-х команд за такт. Производительность в Гигафлопсах получается в пике за счет темпа выполнения команд комплексного умножения двух аргументов (a + bi) * (c+di), в результате получаем 6 операций на клетку, умножаем на 4 клетки и получаем 24 операции за такт. Умножив количество операций за такт на частоту (для R1 это 100 МГц) получим 2,4 ГФлопса.
Подробнее ознакомиться с архитектурой можно в статье «Мультиклеточный процессор — это что?»
3. Что нового в процессоре R1
Первоначально предполагалось немножко доработать процессор P1, но в процессе доработки у R1 получилось практически полностью новое ядро. Теперь память программ общая для всех клеток, соответственно изменился механизм выборки (в P1 у каждой клетке была своя память программ), изменился механизм распределения результатов. Появилась косвенная адресация, добавились команды прямого чтения и записи (минуя механизм очередности), улучшена работа с индексными регистрами. И самое главное, появилась реконфигурация (способность клеток объединяться в группы).
Увеличился ассортимент команд ассемблера, появился блок работы с памятью DTC. Для тактирования достаточно кварца на 8-12 МГц, появилась возможность работать с внешней памятью типа SRAM, SDRAM, PROM, I/O. USB теперь стандарта 2.0 device, RTC с календарем на борту. И важным шагом стала работа аналоговых блок, в процессоре R1 содержится 8 независимых каналов дельта-сигма АЦП 16 бит, 48 киловыборок в секунду и 1 канал ЦАП до 100 мегавыборок в секунду(работает на системной частоте). Первоначально планировалось, что будет два канала ЦАП, но получился один полностью работающий канал ЦАП.
Рассмотрим чуть подробнее несколько нововведений в процессоре R1. Но для начала напомню как выглядит пример параграфа на ассемблере (для P1 и R1 можно писать и на Си):
habr:
getl 1 ;загружаем число 1 в коммутатор
getl 2 ;загружаем число 2 в коммутатор
addl @1, @2 ;выполняем сложение 1 + 2
getl 0x10000 ;загружаем число 0x10000 в коммутатор
wrl @2, @1 ;записываем результат сложения в память по адресу 0x10000
setl #0, @2 ;загружаем адрес памяти в нулевой регистр
jmp habrahabr ;переходим на следующий параграф
complete
habrahabr:
getl #0 ;получаем значение нулевого регистра
rdl @1 ;считываем значение из памяти по адресу 0x10000
getl 3 ;загружаем число 3 в коммутатор
addl @1, @2 ;складываем 3 + 3
wrl @1, 0x10000 ;записываем число 6 в память по адресу 0x10000
jmp next
complete
Косвенная адресация
Введение косвенной адресации позволяет взять значение из памяти по выражению, записанному в качестве второго аргумента функции. Данный тип адресации позволяет повысить быстродействие и упростить код программы.
Рассмотрим простой пример:
Paragraph:
getl 0x50
wrl @1, 0x10
getl 0x12345
wrl @1, 0x50
setl #0, 0x10
jmp Paragraph1
complete
«БЕЗ косвенной адресации»
Paragraph1:
rdl #0 ;результат 0x50
rdl @1 ;результат 0x12345
complete
«C косвенной адресацией»
Paragraph1:
rdl [#0] ;результат 0x12345
complete
В параграфе с косвенной адресацией сначала будет получено значение #0 равное 0x10, затем по данному адресу будет считано значение из памяти равное 0x50 и после этого выполнится чтение rdl по адресу 0x50, результатом которого будет число 0x12345. Без применения косвенной адресации в данном случае потребуется две команды.
В качестве значения в квадратных скобках результат выполнения какой-либо команды, выражение в виде суммы с константой, системный регистр, регистр общего назначения или индексный регистр.
Дополнительные команды
Система команд значительно расширилась в новой версии процессора, появились команды подсчета единиц, копирования флагов, различных сравнений и многое др. Продемонстрируем работу новых команд ge и lt для перехода по различным отрезкам.
Кратко поясним функции команд:
1) синтаксис: ge ARG1, ARG2 — проверка условия «больше или равно»
результат: «1» если ARG1 >= ARG2, иначе 0
2) синтаксис: lt ARG1, ARG2 — проверка условия «меньше»
результат: «1» если ARG1 < ARG2, иначе 0
Пусть у нас есть участки от 0 до 3, от 4 до 10, от 11 и более. При значениях переменной Х необходимо осуществить переход на соответствующий параграф, покажем на примере:
Paragraph_pie:
var := rdl X ;входной параметр
ge @var, -1 ;больше -1, т.е. от 0 для целых чисел
lt @var, 3 ;меньше либо равно 3
and @1, @2 ; операция and
jne @1, parag_0to3 ;переход если оба сравнения вернули «1»
ge @var, 3
lt @var, 10
and @1, @2 ; операция and
jne @1, parag_4to10 ;переход если оба сравнения вернули «1»
ge @var, 10
jne @1, parag_11over ;переход если сравнение вернуло «1» в результате
complete
Хотелось ещё показать пример работы даже не команды, а нового регистра DFADDR, который можем быть полезен, например, для оптимизации конструкции в Си switch-case. Пример кода на Си и аналогичного параграфа:
switch(Var)
{
case 1:
func1();
break;
case 2:
func2();
break;
case 3:
func3();
break;
default:
go_to_default();
break;
}
Switch_case0:
setl #DFADDR, go_to_default ;задаем параграф перехода, если не сработал ни один переход
p1:= rdl Var
subl @p1, 1
je @1, func1
subl @p1, 2
je @1, func2
subl @p1,3
je @1, func3
complete
4. Сравним процессоры P1 и R1
Сравнение начнем с тактирования. Для процессора P1 был необходим генератор тактовой частоты на 80, 100 или 120 МГц. В R1 появился блок PLL и теперь достаточно кварца на 8-12 МГц.
Для работы программы в P1 нужна внешняя флешка, из которой программа перекачивается в оперативную память процессора. В R1 программа может быть также загружена из флешки, а благодаря появившемуся контроллеру внешней памяти возможно выполнение и работа с SRAM, SDRAM памятью и другими по интерфейсу I/O. Кроме того процессор R1 может быть закорпусирован со встроенной флешкой на борту.
Поскольку появился блок управления внешней памятью, то появилась необходимость в перекладывании данных, этим в R1 занимается блок DTC, который способен работать и с регистрами и по прерываниям и с периферией. В R1, в отличие от P1, работают все прерывания.
Количество памяти в R1 возросло до 512 Кбайт с полным доступом к памяти данных и программ и выполнением команд из любой области памяти. В P1 было 128 Кбайт памяти программ, доступа к которой на чтение и запись у пользователя не было и 128 Кбайт памяти данных.
По периферийным блокам подробная информация была приведена выше. Добавлю, что теперь операции с плавающей запятой в R1 двойной точности.
И самое главное, что появилось в R1 – это реконфигурация, т.е. способность клеток объединяться в группы без перезагрузки процессора и перераспределяться. Например, две клетки могут заниматься вычислением, одна клетка периферией и передачей информации, оставшаяся клетка анализом датчиков и если потребуется, то во время работы процессора «прямо на лету» возможно сделать так, чтобы 3 клетки стали заниматься вычислениями, а одна опросом датчиков и периферией. По реконфигурации будет отдельная статья с примерами, пока лишь скажу, что работать с реконфигурацией очень просто, на Си это будет просто вызов одной функции типа fork() с указанием сколько клеток от основного потока мы отделяем и куда, на ассемблере также просто, приведу пример ассемблерной вставки для выполнения трех независимых программ на Си:
Допустим у нас есть 3 программы на Си, в которых мы указываем вместо main():
main1(), main2(), main3(), далее сделаем следующую ассемблерную вставку:
pre_reconf:
getl #PSW
getl 0x180 ; выставляем необходимые биты в PSW
or @1, @2
setl #PSW, @1
jmp reconf
complete
reconf:
getl 0x8
patch @1, @1
setq #ICR, @1 ; 1000 регистры ICR для клеток, указываем в какой группе они будут
getl 0x1
patch @1, @1
setq #ICR, @1 ; 0001
getl 0x6
patch @1, @1
setq #ICR, @1 ; 0110
getl 0x8
getl main3;
patch @2, @1
setq #NEWADDR, @1 ; указываем адрес перехода для группы из 3-й клетки
getl 0x1
getl main2;
patch @2, @1
setq #NEWADDR, @1 ; указываем адрес перехода для группы из 0-й клетки
getl 0x6
getl main1
patch @2, @1
setq #NEWADDR, @1 ; указываем адрес перехода для группы из 1-й и 2-й клетки
complete
Приведём сравнительную таблицу основных параметров P1 и R1:
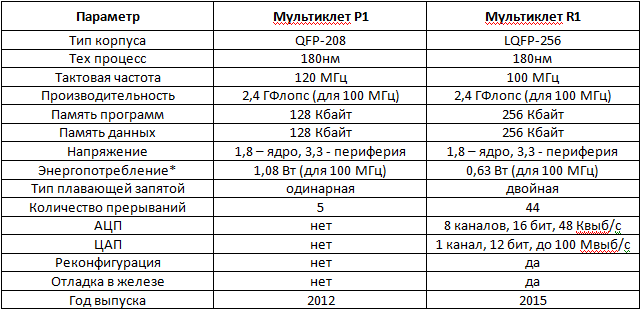
*Энергопотребление приведено на смеси задач 75% DMAC + 25% ADD. Максимальное потребление для R1 на задаче FFT составит 1,05 Вт. Энергопотребление P1 не имеет больших изменений в зависимости от задачи.
В R1 уже реализован для некоторых блоков clock gating для снижения энергопотребления, при этом количество транзисторов в R1 в 1,5 раза больше чем в P1.
Для каждого процессора имеется возможность писать программы на ассемблере, Си, отлаживать их и выполнять на процессоре. В качестве среды разработки выбран простой редактор Geany.
Работать в среде можно под Windows и Linux. Обзор среды разработки и средств также будет выделен в отдельную статью.
5. Анонс
Хочется поделиться тем, что процессор R1 работает, как и планировали, отладочные платы под него откорретированы и уже мы сами сделали прототип защищенного криптотелефона с использованием реконфигурации и встроенных АЦП, ЦАП. Примерный вид корпуса изображен на рисунке 4. Работающий макет на рисунке 5.

Рис 4. Прототип корпуса телефона
Рис 5. Работающий макет криптотелефона
Сейчас у нас идёт активная фаза по внедрению наших процессоров в школы (в виде робототехнических занятий) и Вузы в виде создания лабораторий, поэтому важным шагом мы считаем снижение порога вхождения в работу с новыми мультиклеточными процессорами.
Для этого мы планируем сделать цикл обучающих статей на портале Хабрахабр, краткий анонс и очередность статей приведу ниже с целью получить отклик в плане порядка выпуска лекций и содержания:
Разделы новых статей
1) Мультиклеточная архитектура глазами программиста
2) Среда разработки для мультиклеточных процессоров – Geany
3) Обзор отладочного комплекта LDM-Systems для Мультиклет R1
4) Запуск первой программы на Мультиклет R1
5) Обзор ассемблера и Си компилятора для Мультиклет
6) Обзор отладчика и среды отладки Geany для Мультиклет
7) Реконфигурация в процессоре Мультиклет R1
8) Системные регистры и сторожевой таймер (Мультиклет R1)
9) Система тактирования (Мультиклет R1)
10) Система прерываний (Мультиклет R1)
11) Работа с памятью и блоком DTC (Мультиклет R1)
12) Работа с портами GPIO (Мультиклет R1)
13) Работа с UART, RS-232, RS-485 в примерах (Мультиклет R1)
14) Интерфейс I2C с разбором примера работы (Мультиклет R1)
15) Интерфейс SPI, особенности и примеры работы (Мультиклет R1)
16) PWM и его особенности (Мультиклет R1)
17) USB 2.0 на простом примере и анализ в Beagle (Мультиклет R1)
18) Ethernet: прием и передача пакетов (Мультиклет R1)
19) Интерфейс I2S на примере работы с аудио кодеком (Мультиклет R1)
20) АЦП и ЦАП с примером реализации диктофона (Мультиклет R1)
21) Математическая библиотека (Мультиклет R1)
22) Библиотека для работы со строковым дисплеем WH1602A (Мультиклет R1)
23) Библиотека для работы с тачскрином HY2B (Мультиклет R1)
24) Библиотека для работы с GSM модулем SIM800(Мультиклет R1)
25) Библиотека для работы с GLONASS/GPS модулем (Мультиклет R1)
26) Библиотека для работы с Ethernet (lwip) (Мультиклет R1)
27) Библиотека для работы с USB (Мультиклет R1)
28) Работа с ОС FreeRTOS (Мультиклет R1)
29) Работа с ОС uClinux (Мультиклет R1)
2) Среда разработки для мультиклеточных процессоров – Geany
3) Обзор отладочного комплекта LDM-Systems для Мультиклет R1
4) Запуск первой программы на Мультиклет R1
5) Обзор ассемблера и Си компилятора для Мультиклет
6) Обзор отладчика и среды отладки Geany для Мультиклет
7) Реконфигурация в процессоре Мультиклет R1
8) Системные регистры и сторожевой таймер (Мультиклет R1)
9) Система тактирования (Мультиклет R1)
10) Система прерываний (Мультиклет R1)
11) Работа с памятью и блоком DTC (Мультиклет R1)
12) Работа с портами GPIO (Мультиклет R1)
13) Работа с UART, RS-232, RS-485 в примерах (Мультиклет R1)
14) Интерфейс I2C с разбором примера работы (Мультиклет R1)
15) Интерфейс SPI, особенности и примеры работы (Мультиклет R1)
16) PWM и его особенности (Мультиклет R1)
17) USB 2.0 на простом примере и анализ в Beagle (Мультиклет R1)
18) Ethernet: прием и передача пакетов (Мультиклет R1)
19) Интерфейс I2S на примере работы с аудио кодеком (Мультиклет R1)
20) АЦП и ЦАП с примером реализации диктофона (Мультиклет R1)
21) Математическая библиотека (Мультиклет R1)
22) Библиотека для работы со строковым дисплеем WH1602A (Мультиклет R1)
23) Библиотека для работы с тачскрином HY2B (Мультиклет R1)
24) Библиотека для работы с GSM модулем SIM800(Мультиклет R1)
25) Библиотека для работы с GLONASS/GPS модулем (Мультиклет R1)
26) Библиотека для работы с Ethernet (lwip) (Мультиклет R1)
27) Библиотека для работы с USB (Мультиклет R1)
28) Работа с ОС FreeRTOS (Мультиклет R1)
29) Работа с ОС uClinux (Мультиклет R1)
Спасибо всем кто дочитал до конца, буду рад конструктивной критике и комментариям.
Поздравляю всех пользователей портала Хабрахабр с днем радио!










