На протяжении многих лет в среде DevOps был популярен подход основанный на «работе над ошибками». Идея заключалась в том, что многие компании сталкиваются с дорогостоящими простоями, потерей прибыли и производительности из-за проблем, связанных с доступными мощностями, поэтому вам нужно было создать собственную прикладную инфраструктуру и ее окружение, чтобы отработать все ошибки и убедиться в том, что это не повторится.

Итогом недавнего оглушительного успеха игры Pokémon Go стало оглушительное разочарование для многих. Особенно для родителей гиперактивных детей, которые хотят играть прямо СЕЙЧАС, но не могут из-за того, что создание учетных записей для игры было временно приостановлено и ограничивалось из-за большой популярности игры.

Можно вспомнить предложение Вернера Фогельса, технического директора Amazon, помочь компании решить проблемы с доступными мощностями, т.к. они «не внедрили облачные технологии», и это была их основная проблема, что для меня не совсем понятно. Действительно, согласно информации Wikipedia о разработчике дополненной реальности, компания обрабатывает «более 200 миллионов игровых действий в день по мере того, как люди взаимодействуют с реальными и виртуальными объектами в реальном мире». Я думаю, что мы можем простить их, или простить могут те, кто понимает возможности совеременных систем обработки информации и ее передачи на расстояния. Что касается описанных «server issues», мы все знаем, что «сервер» – это техническое обозначение для «15 различных компонентов, используемых в прикладной и сетевой инфраструктуре».
В любом случае, вывод таков: облачные технологии не обязательно лучше ведут себя в случае неожиданного успеха проекта. Это может быть, но не из-за облачных технологий. Дело в том, что облачные технологии созданы не только для того, чтобы проводить «работу над ошибками», но они также созданы для того, чтобы масштабироваться.
Я не могу сказать, почему Niantic Labs не смогла справиться с большим спросом на игру. Возможно, что не хватило емкости, в таком случае можно было бы воспользоваться облачными технологиями. Возможно, дело в том, что приложение и/или инфраструктура не поддерживают масштабирование, в таком случае облачные технологии могли бы оказаться бесполезными. Дело не в том, что мы должны ругать их за то, что они сделали/не сделали. Дело в том, что они являются отличным примером того, что происходит в мире приложений – компании должны готовиться как к успеху, так и к неудаче. И не только к успеху, который приходит постепенно, но и к мгновенному успеху, как это было в случае с Pokémon Go.
Потому что если это случается, вам не захочется, чтобы успешный провал заполнил весь Интернет.
Основным источником проблем с масштабируемостью являются источники данных. Давние пользователи Twitter помнят, что при появлении социальных сетей наблюдались проблемы с масштабируемостью баз данных. Сервис PayPal был одним из первых и самых ярых сторонников фрагментации в качестве стратегии масштабирования, и эта методика была выбрана в качестве общего решения, применяемого к базам данных, сервисам и приложениям. Рост популярности NoSQL объяснялся более высоким уровнем масштабируемости по сравнению с традиционными реляционными базами данных.
Другим источником проблем с масштабируемостью является инфраструктура. Автоматическое масштабирование в облачных средах основывается на способности не только добавлять больше вычислительных ресурсов, но и на увеличении емкости точки входа в приложение. В любой архитектуре использование масштабирования для увеличения емкости подразумевает использование какого-либо сервиса балансировки нагрузки. Когда вычислительная мощность увеличивается, это должно быть зарегистрировано с помощью сервиса балансировки нагрузки. Это подразумевает использование интерфейсов программирования приложений, скриптов, функций автоматизации и управления. Эти компоненты должны иметься до того, как они понадобятся.
Включение сервиса балансировки нагрузки в любой – каждой – архитектуре приложений должно быть обязательным. Сервис балансировки нагрузки нужен может помочь и в работе над ошибками, т.к. он способен решать вопросы с неправильной работой приложений, но он также поддерживает потребность «работе над мастабированием». Но не стоит думать, что дело сводится просто к размещению сервиса балансировки нагрузки перед приложениями. Важно предусмотреть функции автоматизации (скрипты) и управления (процессы), которые обеспечат автоматическое масштабирование для удовлетворения растощего спроса, когда он появится. Масштабирование сегодня связано с архитектурой, а не с алгоритмами, очень важно понять это заранее, до появления проблем.
Если честно, Niantic Labs проделала хорошую работу, создавая, чтобы не работало. Проблемы с емкостью встречались дружелюбными сообщениями, а не страница кода состояния HTTP, как это часто бывает. Они отнеслись к этому с юмором и описали неполадки просто и понятно. К чему бы они не готовились, компания получила неожиданный успех. И это будет хорошим напоминанием, что создание для масштабирования так же важно, как и работа над ошибками.
Потому что если вы не сделаете этого, кто-то другой обязательно сделает.
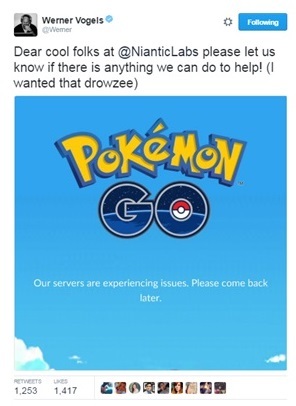
Итогом недавнего оглушительного успеха игры Pokémon Go стало оглушительное разочарование для многих. Особенно для родителей гиперактивных детей, которые хотят играть прямо СЕЙЧАС, но не могут из-за того, что создание учетных записей для игры было временно приостановлено и ограничивалось из-за большой популярности игры.

Можно вспомнить предложение Вернера Фогельса, технического директора Amazon, помочь компании решить проблемы с доступными мощностями, т.к. они «не внедрили облачные технологии», и это была их основная проблема, что для меня не совсем понятно. Действительно, согласно информации Wikipedia о разработчике дополненной реальности, компания обрабатывает «более 200 миллионов игровых действий в день по мере того, как люди взаимодействуют с реальными и виртуальными объектами в реальном мире». Я думаю, что мы можем простить их, или простить могут те, кто понимает возможности совеременных систем обработки информации и ее передачи на расстояния. Что касается описанных «server issues», мы все знаем, что «сервер» – это техническое обозначение для «15 различных компонентов, используемых в прикладной и сетевой инфраструктуре».
В любом случае, вывод таков: облачные технологии не обязательно лучше ведут себя в случае неожиданного успеха проекта. Это может быть, но не из-за облачных технологий. Дело в том, что облачные технологии созданы не только для того, чтобы проводить «работу над ошибками», но они также созданы для того, чтобы масштабироваться.
Я не могу сказать, почему Niantic Labs не смогла справиться с большим спросом на игру. Возможно, что не хватило емкости, в таком случае можно было бы воспользоваться облачными технологиями. Возможно, дело в том, что приложение и/или инфраструктура не поддерживают масштабирование, в таком случае облачные технологии могли бы оказаться бесполезными. Дело не в том, что мы должны ругать их за то, что они сделали/не сделали. Дело в том, что они являются отличным примером того, что происходит в мире приложений – компании должны готовиться как к успеху, так и к неудаче. И не только к успеху, который приходит постепенно, но и к мгновенному успеху, как это было в случае с Pokémon Go.
Потому что если это случается, вам не захочется, чтобы успешный провал заполнил весь Интернет.
Основным источником проблем с масштабируемостью являются источники данных. Давние пользователи Twitter помнят, что при появлении социальных сетей наблюдались проблемы с масштабируемостью баз данных. Сервис PayPal был одним из первых и самых ярых сторонников фрагментации в качестве стратегии масштабирования, и эта методика была выбрана в качестве общего решения, применяемого к базам данных, сервисам и приложениям. Рост популярности NoSQL объяснялся более высоким уровнем масштабируемости по сравнению с традиционными реляционными базами данных.
Другим источником проблем с масштабируемостью является инфраструктура. Автоматическое масштабирование в облачных средах основывается на способности не только добавлять больше вычислительных ресурсов, но и на увеличении емкости точки входа в приложение. В любой архитектуре использование масштабирования для увеличения емкости подразумевает использование какого-либо сервиса балансировки нагрузки. Когда вычислительная мощность увеличивается, это должно быть зарегистрировано с помощью сервиса балансировки нагрузки. Это подразумевает использование интерфейсов программирования приложений, скриптов, функций автоматизации и управления. Эти компоненты должны иметься до того, как они понадобятся.
Включение сервиса балансировки нагрузки в любой – каждой – архитектуре приложений должно быть обязательным. Сервис балансировки нагрузки нужен может помочь и в работе над ошибками, т.к. он способен решать вопросы с неправильной работой приложений, но он также поддерживает потребность «работе над мастабированием». Но не стоит думать, что дело сводится просто к размещению сервиса балансировки нагрузки перед приложениями. Важно предусмотреть функции автоматизации (скрипты) и управления (процессы), которые обеспечат автоматическое масштабирование для удовлетворения растощего спроса, когда он появится. Масштабирование сегодня связано с архитектурой, а не с алгоритмами, очень важно понять это заранее, до появления проблем.
Если честно, Niantic Labs проделала хорошую работу, создавая, чтобы не работало. Проблемы с емкостью встречались дружелюбными сообщениями, а не страница кода состояния HTTP, как это часто бывает. Они отнеслись к этому с юмором и описали неполадки просто и понятно. К чему бы они не готовились, компания получила неожиданный успех. И это будет хорошим напоминанием, что создание для масштабирования так же важно, как и работа над ошибками.
Потому что если вы не сделаете этого, кто-то другой обязательно сделает.










