
На сегодняшний день смысл в том, чтобы прислушиваться к обратной связи от всех посетителей, практически отсутствует. По крайней мере не стоит пытаться получить всю информацию сразу.
На стартовом этапе нового проекта, особенно если управление тем или иным продуктом осуществляется не так давно, возникает большой соблазн узнать мнение всех пользователей по тому или иному вопросу. Но чаще всего такая поспешность является ошибочной. Кроме спешки большинство специалистов, занятых продвижением тех или иных продуктов, допускают 5 основных ошибок, которые повторяются вновь и вновь. Наличие множества сервисов обратной связи делает получение информации от пользователей крайне простым процессом – однако не стоит увлекаться ее получением по любому поводу. Мы подготовили для вас пять советов, связанных с использованием обратной связи от потенциальных клиентов.
1. НЕ СТОИТ ОБРАЩАТЬСЯ КО ВСЕМ ПОЛЬЗОВАТЕЛЯМ СРАЗУ
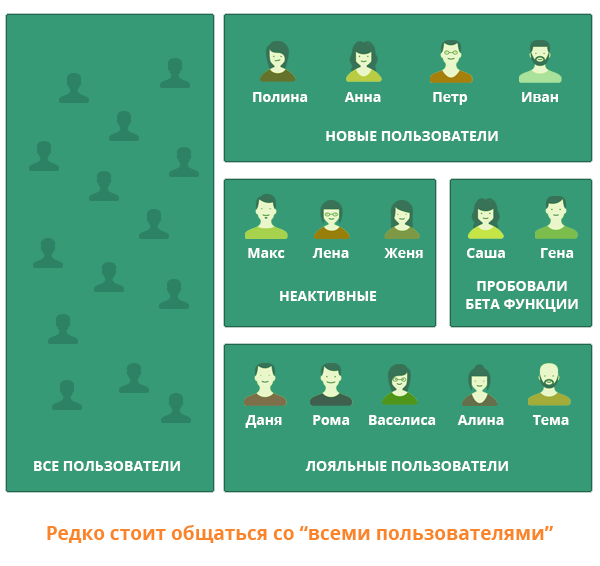
Исследуя мнение всех пользователей сразу, вы игнорируете поведенческую специфику каждого из них. Согласитесь, что для целей продакт-менджмента глупо сваливать в одну кучу тех, кто пришел к вам пару дней назад и тех, кто сотрудничает с вами долгие годы. Тех, кто использует ваш продукт каждый день и тех, кто заходит в систему раз в месяц, чтобы обновить биллинговые данные.
Решить данную проблему не так уж сложно. Разбивайте пользователей на сегменты, например:
Если стоит задача улучшить способы привлечения новых посетителей, то необходимо опросить тех, кто подписался относительно недавно.
Если требует доработать тот или иной функционал – обратитесь к тем, кто его использует.
Хотите разобраться, почему клиенты не пользуются определенным сервисом? Опросите тех, кто его не применяет.
Если необходимо провести «тестинг» продукта и установить проблемные зоны, то наладьте контакт только с активными пользователями, которые постоянно пользуются всеми функциями продукта.
2. СДЕЛАЙТЕ ОБРАТНУЮ СВЯЗЬ ПОСТОЯННОЙ
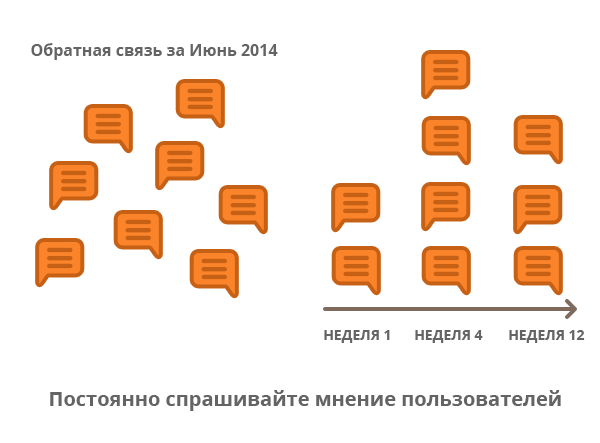
Сущность обратной связи предполагает, что разработчик продукта сам инициирует ее получение. Это означает, что после того, как появилась необходимость обратной связи, вам нужно ждать некоторое время и ничего не делать, получая и анализируя отзывы. Чтобы компенсировать это, вы накапливаете и задаете пользователям еще больше вопросов, после чего длительное время ожидаете ответы. Особенно глупой будет реакция на каждый отзыв, вместо того, чтобы дождаться всех данных и проанализировать всю их совокупность.
Проблема тут имеет две стороны: во-первых, информация от пользователей поступает не в тот момент, когда она нужна, во-вторых, отзывы пользователей поступают только тогда, когда вы задаете им вопрос. Именно так можно упустить момент, когда продукт требует немедленной доработки.
Решение: Проводите опросы клиентов регулярно. Самый простой, но весьма эффективный способ – попросить пользователя прислать свой отзыв и пожелания, например, на 30-й, 60-й, 120-й, 365-й день использования продукта. Современные сервисы позволяют провести такую настройку за пару минут, а окупается подобный подход всего за пару дней.
Более сложный способ – получение обратной связи по периодичности пользования отдельными функциями. Например, если ваш продукт имеет календарь, то вы можете задать вопрос пользователям после 15-го, 30-го и 60-го обращения к отдельной функции – именно так можно добиться более осмысленной и структурированной обратной связи: при первом использовании человек скажет вам, что непонятно, на 15-ом – что ему хотелось бы поменять, на 60-м – какие ограничения имеются у вашего продукта.
3. РАЗДЕЛИТЕ ОТЗЫВЫ ПЛАТНЫХ И БЕСПЛАТНЫХ ПОДПИСЧИКОВ
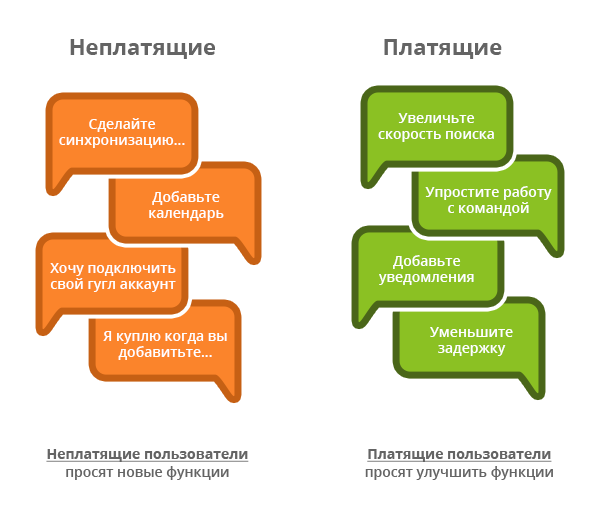
Несложно проследить связь с советом №1. Конечно, проще всего рассматривать всю совокупность отзывов без учета типа подписки. В целом так можно действовать до определенного порога (например, для клиентов, которые платят 500-3500 рублей в месяц), однако разница между запросами от бесплатных и платных подписчиков все же существенна. Пользователи бесплатных сервисов безусловно смогут улучшить ваши бесплатные пакеты, но едва ли ваш бизнес ориентирован именно на это. Чаще всего бесплатные пакеты создаются для привлечения новых пользователей, чтобы потом они перешли на платную подписку. Не стоит обращать внимания на отзывы следующего типа:
Перейду на платную подписку, если…
Перейду на платный, когда…
Принимать обещания в бизнесе – не продуктивно. Обращайте внимание на то, что происходит на самом деле.
Итак, несколько советов по решению:
Чтобы улучшить условия пользования продуктов для платных подписчиков, обращайтесь только к платным подписчикам
Чтобы узнать мотивацию перехода с бесплатной на платную подписку, обращайтесь только к перешедшим пользователям
Чтобы улучшить бесплатные пакеты, обращайтесь только к бесплатным пользователям, но старайтесь не идти у них на поводу – такие пользователи не приносят вам прибыли, а, скорее всего, просто запросят больше бесплатных функций.
4. НЕ СЛУШАЙТЕ ШУМНОЕ МЕНЬШИНСТВО
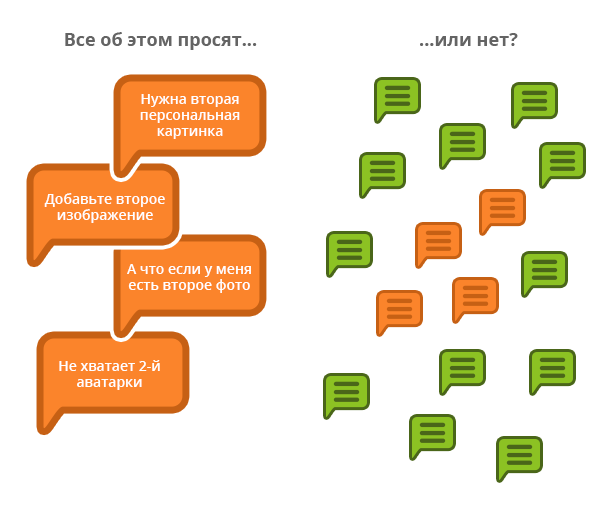
Среди маркетологов распространена шутка о том, что множественное число от слова «мнение» — вовсе не «данные». Это, конечно же, не значит, что мнение одного клиента обязательно бесполезно. Но если однажды к вам обратятся 10 пользователей с просьбой улучшить, например, управление календарем, то не нужно сразу начинать проект по доработке продукта. Сначала нужно узнать, насколько этот десяток клиентов представляет общее мнение с помощью опроса всех пользователей данного функционала.
Решение: каждый получаемый отзыв пользователей должен восприниматься в первую очередь как гипотеза, которую необходимо проверить. Но даже после того, как вы обнаружили, что все пользователи сходятся во мнении, не стоит сразу начинать этап реализации предложения.
Следует провести более тщательный анализ – именно об этом наш последний совет.
5. НЕ СЧИТАЙТЕ ПО УМОЛЧАНИЮ, ЧТО ВСЕ ПОЛЬЗОВАТЕЛИ ПРЕДЛАГАЮТ ПРАВИЛЬНОЕ РЕШЕНИЕ
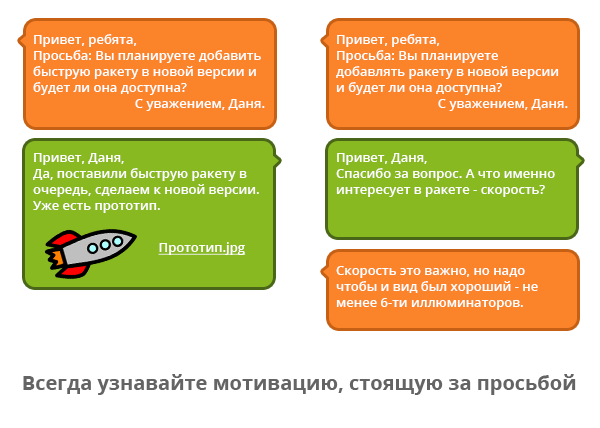 rocket
rocketНемного перефразируем Конфуция:
Когда клиент показывает на луну, наивный продакт-менеджер изучает его палец.
Пресловутая история Генри Форда про мнение потребителей (“Если бы я спросил людей, чего они хотят, они бы попросили более быструю лошадь”) часто используется как оправдание для игнорирования пожеланий клиентов. Но не в нашем случае: если клиенту нужна лошадь побыстрее, то на самом деле его ключевое требование – скорость перемещения. Самое время сесть и подумать, как же его воплотить в жизнь. В прошлом примере с мнением 10-ти человек мы говорили о их просьбе улучшить управление календарем. Можно сразу же садиться и корректировать форму и содержание продукта, но очень часто это не имеет никакого смысла. Опросив всех пользователей, мы скорее всего выясним, что дело не в сложности формы управления календарем, а в частоте его использования.
Решение: необходимо помнить, что каждый запрос пользователей – это сложнейшее сочетание личностных навыков клиента, степени его знакомства с продуктом, а также особенностей восприятия проблем и наличия фантазии. Клиент не знает вашего видения продукта и не представляет сложность реализации того или иного сервиса. Именно поэтому мнение клиента – не руководство к действию, а лишь возможность взглянуть на проблему с другой точки зрения и найти то решение, которое окажется выгодным для вас и удобным для пользователей.
Безусловно, многие советы ваших клиентов будут прекрасно сочетаться с иными свойствами продукта и идеально вписываться в его концепцию. В таких случаях необходимо включать интуитивное понимание того, что вы предлагаете пользователям, чтобы вместе с ними с легкостью находить пути совершенствования продукта.
Надеемся, описанные ошибки помогут вам построить эффективное общение с вашими пользователями и улучшат ваш сервис.
Хорошей вам обратной связи, и крутых продуктов!
Да, и заходите к нам, оставляйте свои отзывы. Будем вместе строить систему общения с пользователями.
