

Еще в начале ноября 2017 года компания Qualcomm Datacenter Technologies (QDT) завершила работу над своим новым детищем — процессором на базе 10-нм технологии — Centriq 2400. Какое будущее ждет индустрию по мнению создателей сего новшества? Какие преимущества получать серверы и чем так уникален Centriq 2400? Об этом и не только читайте далее.
8 ноября в Сан-Хосе (Калифорния) прошла пресс-конференция компании QDT, на которой и было официально анонсировано начало поставок нового процессора. Старший вице-президент и главный менеджер компании Ананд Чандрасехер по этому поводу заявил:
Сегодняшняя презентация является важным достижением и кульминацией более 4 лет усердного проектирования, разработки и поддержки системы… Мы создали самый продвинутый серверный процессор в мире, который предоставляет высокую производительность в совокупности с высоким уровнем энергоэффективности, позволяющий нашим клиентам значительно уменьшить свои затраты.
Помимо неприкрытой гордости за свой продукт, представители компании не стесняются заявлять, что их процессор Centriq 2400 значительно превосходит продукты-конкуренты, к примеру Intel Xeon Platinum 8180. По их подсчетам, на каждый потраченный доллар (а стоимость процессора составляет $1995) пользователь получит производительность в 4 раза. А при перерасчете в производительность на 1 ватт — на 45% больше. Смелые заявления, однако многие из представителей различных компаний, заинтересованных в новинке, более чем рады их услышать.
Технические данные Qualcomm Centriq 2400
Архитектура CPU:
- до 48 64-битных ядер с пиковой частотой в 2.6 ГГц;
- Armv8-совместимость;
- только AArch64;
- Armv8 FP/SIMD;
- Расширение CRC и Armv8 Crypto;
Кэш CPU:
- 64 Кб кэша команд (инструкций) L1 и 24 Кб одноциклового кеша L0;
- 32 Кб кэша данных L1;
- 512 Кб общего кэша L2 на каждые 2 ядра;
- 60 Мб общего кэша L3;
- фильтрация межпроцессорных запросов L2;
- QoS;
где, L (L1, L2, L3, L0) — уровень, т.е. L0 — нулевой уровень.
Технология:
- 10-нм технологии FinFET от Samsung;
Пропускная способность памяти:
- 6 каналов подключения модулей памяти DDR4;
- до 2667 МТ/с на одно подключение;
- 128 ГБ/с — максимальная общая пропускная способность;
- Встроенное сжатие полосы пропускания;
Объем памяти:
- 768 ГБ = 128 ГБ х 6 подключений;
Тип памяти:
- 64-битные DDR4 подключения с 8-битным ECC;
- RDIMM и LRDIMM;
Поддерживаемый интерфейс:
- GPIO;
- I²C;
- SPI;
- 8-полосный SATA Gen 3;
- 32 PCIe Gen3 с возможностью подключения до 6 контроллеров PCIe;
Помимо вышеуказанных характеристик стоит отметить, что данный процессор имеет по 18 миллиардов транзисторов на каждом чипе. А все его ядра связаны двунаправленной кольцевой шиной. При максимальной нагрузке Centriq 2400 потребляет всего 120 Вт.
Основной направленностью нового процессора все же остаться облачные решения. По словам представителей компании, Centriq 2400 позволит создать серверные системе, которые будут отличаться высокой производительностью, эффективностью и масштабируемостью.
Это не могло не привлечь множество компаний, облачные технологии для которых являются чуть ли не основой их деятельности. На презентации побывали: Alibaba, LinkedIn, Cloudflare, American Megatrends Inc., Arm, Cadence Design Systems, Canonical, Chelsio Communications, Excelero, Hewlett Packard Enterprise, Illumina, MariaDB, Mellanox, Microsoft Azure, MongoDB, Netronome, Packet, Red Hat, ScyllaDB, 6WIND, Samsung, Solarflare, Smartcore, SUSE, Synopsys, Uber, Xilinx. Список довольно внушительный, что говорит о повышенном внимании к данному продукту.
На данный момент процессор Qualcomm Centriq 2400 только набирает обороты, как в распространенности, так и в популярности. Что, естественно, приведет к появлению чего-то нового, подобного или даже более производительного, со стороны конкурентов компании QDT.
Но далеко не все слепо верят в крутость новинки. Если и те, кто считает, что проведение тестов и сравнительного анализа нескольких процессоров позволит увидеть куда более показательные результаты, нежели слова промоутеров Centriq 2400.
Компания Cloudflare провела сравнительный анализ трех платформ: Grantley (Intel), Purley (Intel) и Centriq (Qualcomm).
Ниже будут представлены графики данного анализа и выводы их автора — Влада Краснова. (Оригинал данного анализа в блоге компании Cloudflare)
Криптография с открытым ключом
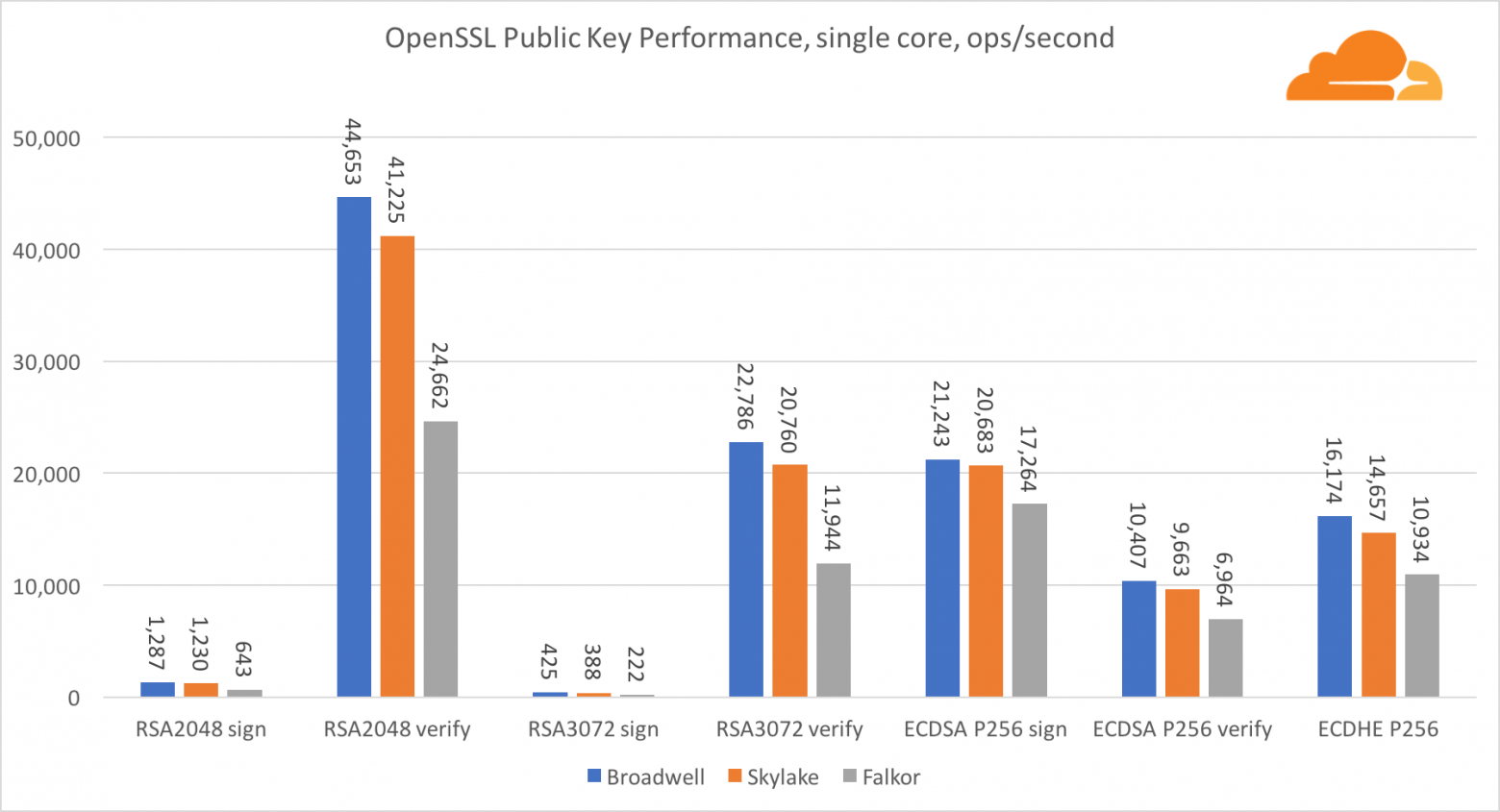
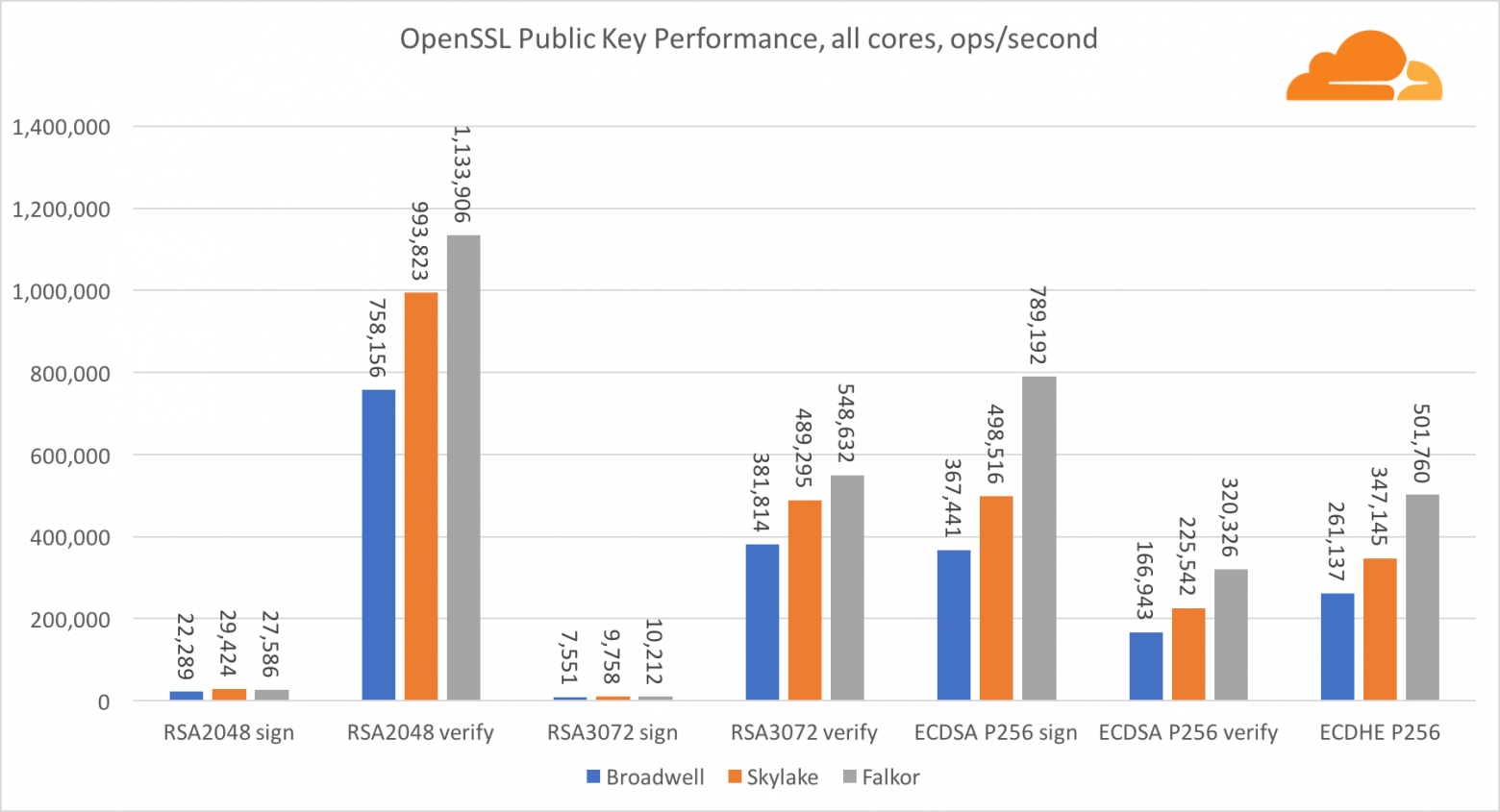
Криптография с открытым ключом — это чистой воды производительность АЛУ (арифметико-логическое устройство). Интересно, но не удивительно, что в одном базовом бенчмарке ядро Broadwell быстрее Skylake, и оба они в свою очередь быстрее, чем Falkor. Это потому, что Broadwell работает на более высокой частоте, хотя в архитектурном плане он не намного уступает Skylake.
Falkor уступает остальным в данном тесте. Во-первых, в одном из базовых бенчмарков был включен режим turbo, означающий, что процессоры Intel работают на более высокой частоте. К тому же в Broadwell Intel представила две специальные инструкции для ускорения обработки больших чисел: ADCX и ADOX. Они выполняют две независимые операции add-with-carry за цикл, тогда как ARM может выполнять только одну. Аналогично, набор инструкций ARMv8 не имеет единой команды для выполнения 64-битного умножения, вместо этого используется пара инструкций MUL и UMULH.
Тем не менее, на уровне SoC, Falkor выигрывает. Он незначительно медленнее, чем Skylake по показателям RSA2048, и только потому, что RSA2048 не имеет оптимизированной реализации для ARM. Производительность ECDSA смехотворно высока. Один чип Centriq может удовлетворить потребности ECDSA практически любой компании в мире.
Также очень интересно видеть, что Skylake превосходит Broadwell на 30%, несмотря на то, что уступил ему в тесте по одному ядру и обладает всего на 20% больше ядер чем Broadwell. Это можно объяснить более эффективным turbo режимом и улучшенной гиперпоточностью.
Симметричная криптография
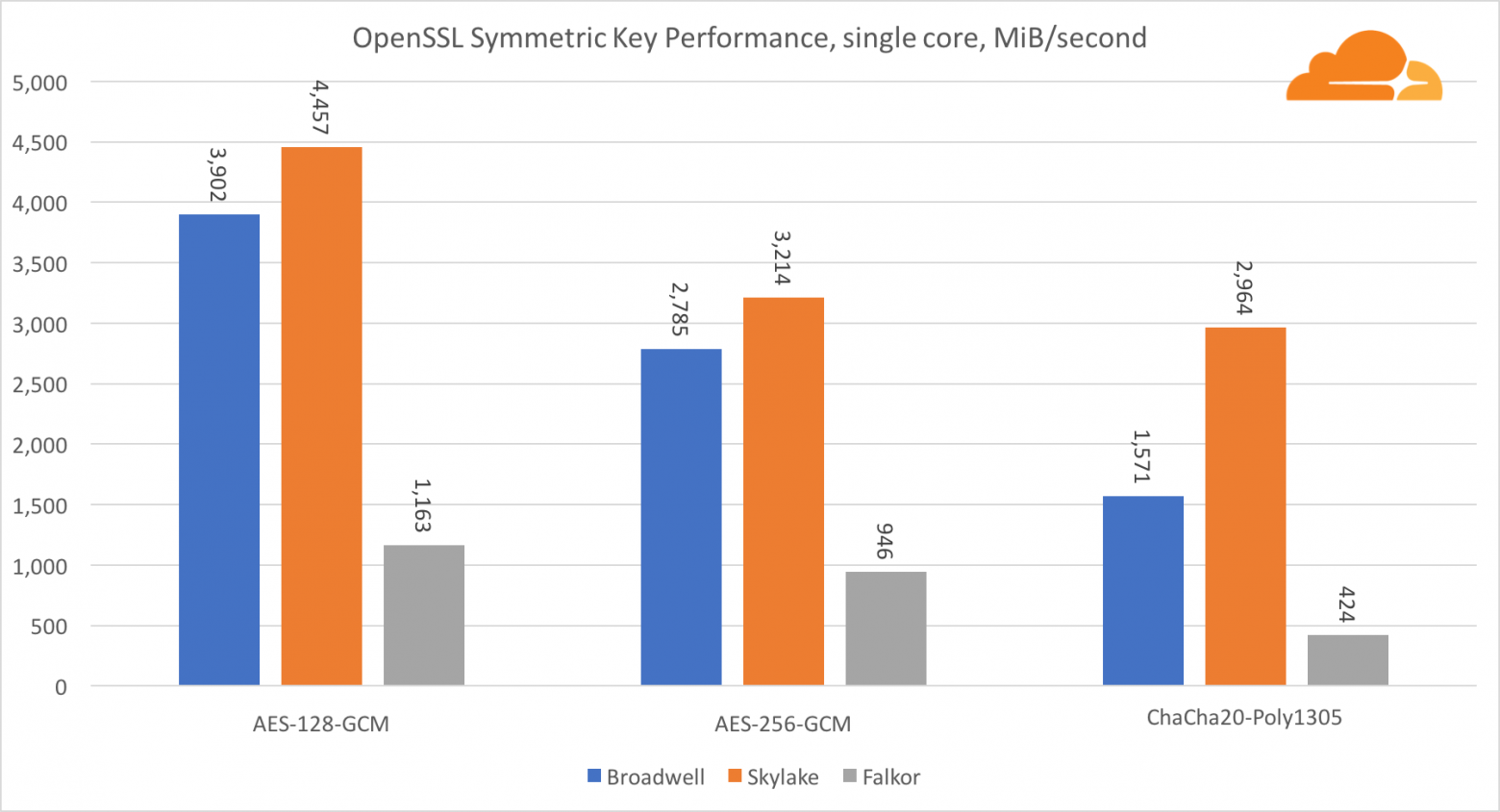
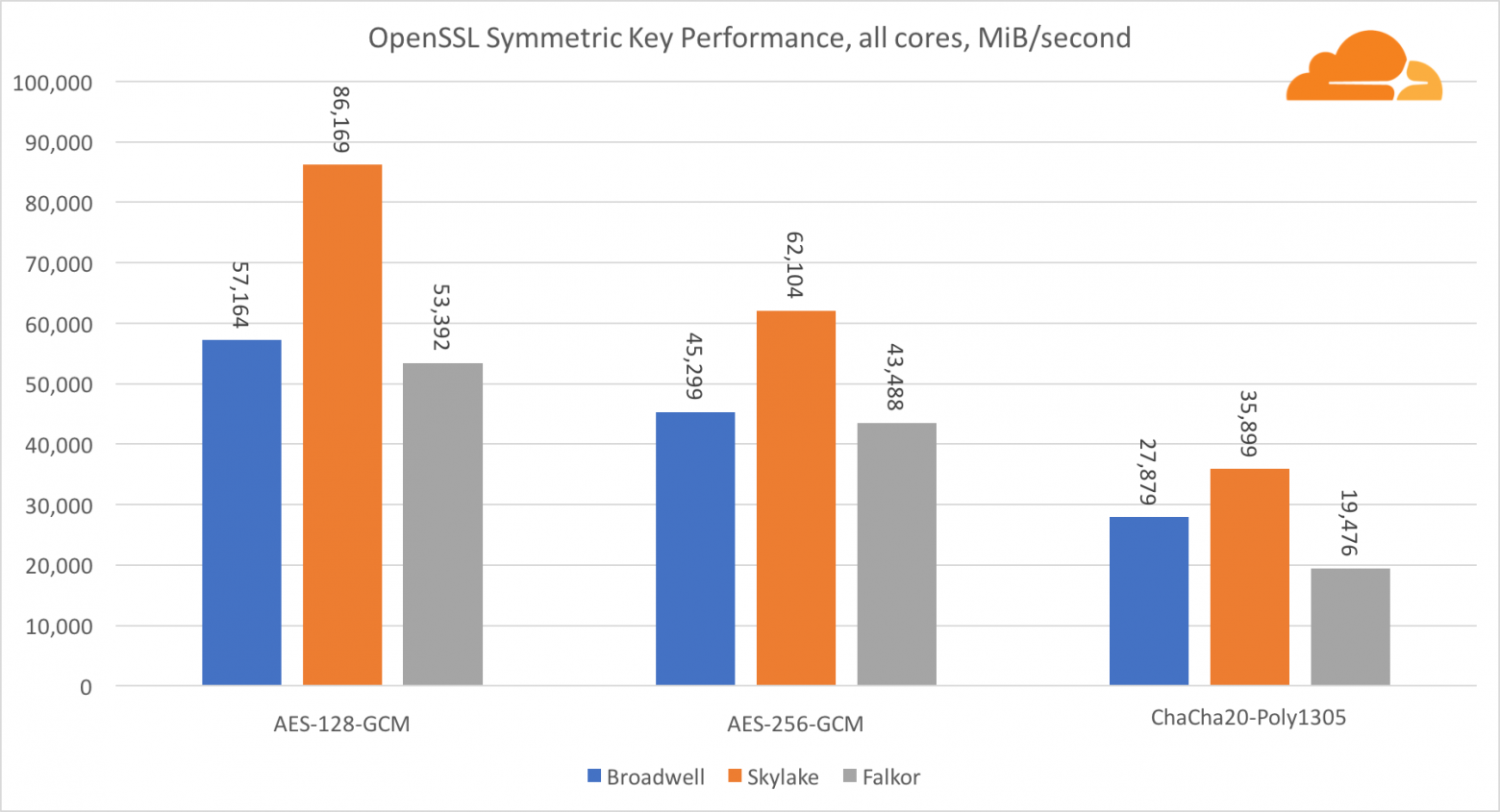
Производительность ядер Intel в симметричной криптографии просто великолепна.
AES-GCM использует комбинацию специальных аппаратных инструкций для ускорения AES и CLMUL. Intel впервые представила эти инструкции еще в 2010 году, с их процессором Westmere и с каждым поколением они улучшали их производительность. Недавно ARM представила набор подобных инструкций с их 64-битным набором команд в качестве необязательного дополнения. К счастью, каждый поставщик оборудования, которого я знаю, реализовал их. Весьма вероятно, что Qualcomm улучшит производительность криптографических инструкций в будущих поколениях.
ChaCha20-Poly1305 — более общий алгоритм, разработанный таким образом, чтобы лучше использовать широкие SIMD-модули. Процессор Qualcomm имеет только 128-битный NEON SIMD, а Broadwell — 256-битный AVX2, а Skylake — 512-битный AVX-512. Это объясняет, почему Skylake с таким отрывом ушел в лидеры по оценке работы с одним ядром. В тесте всех ядер одновременно отрыв Skylake от остальных сократился, поскольку он должен снизить тактовую частоту при выполнении рабочих нагрузок AVX-512. При выполнении AVX-512 на всех ядрах базовая частота уменьшается до 1,4 ГГц. Помните об этом, если вы смешиваете AVX-512 и другой код.
Выводом касательно симметричной криптографии является то, что хоть Skylake и лидирует, Broadwell и Falkor показали очень неплохие результаты, имея достаточно высокую производительность для реальных случаев, учитывая тот факт, что на нашей стороне RSA потребляет больше процессорного времени, чем все другие криптоалгоритмы, вместе взятые.
Компрессия (сжатие)
Следующий тест, который я хотел провести, это компрессия. По двум причинам. Во-первых, это важная рабочая нагрузка, поскольку чем лучше компрессия, тем меньше нужно пропусков способности, а это позволяет быстрее доставлять контент клиенту. Во-вторых, это очень требовательная рабочая нагрузка с высокой частотой Branch misprediction.
Очевидно, что первым тестом будет популярная библиотека zlib. В Cloudflare мы используем улучшенную версию библиотеки, оптимизированную для 64-разрядных процессоров Intel, и хотя она написана в основном на языке C, она использует некоторые специфические для Intel встроенные функции. Сравнивать эту оптимизированную версию с оригинальной zlib было бы несправедливо. Но не волнуйтесь, немного усилий и я адаптировал библиотеку так, чтобы она работала на ARMv8 архитектуре, с использованием свойств NEON и CRC32. При этом скорость ее в 2 раза больше чем у оригинальной, для некоторых файлов.
Второй тест — это новая библиотека brotli, написанная на языке С и позволяющая использовать равные условия для всех платформ.
Все тесты проведены на HTML blog.cloudflare.com, в памяти, подобно тому, как NGINX производит потоковое сжатие. Разве конкретной версии HTML файла 29329 байта, что является хорошим показателем, поскольку соответствует размер большинству файлов, которые мы сжимаем. Тест параллельного сжатия — это параллельное сжатие нескольких файлов одновременно, одиночного — сжатие одного файла в несколько потоков, аналогично тому, как работает NGINX.
gzip
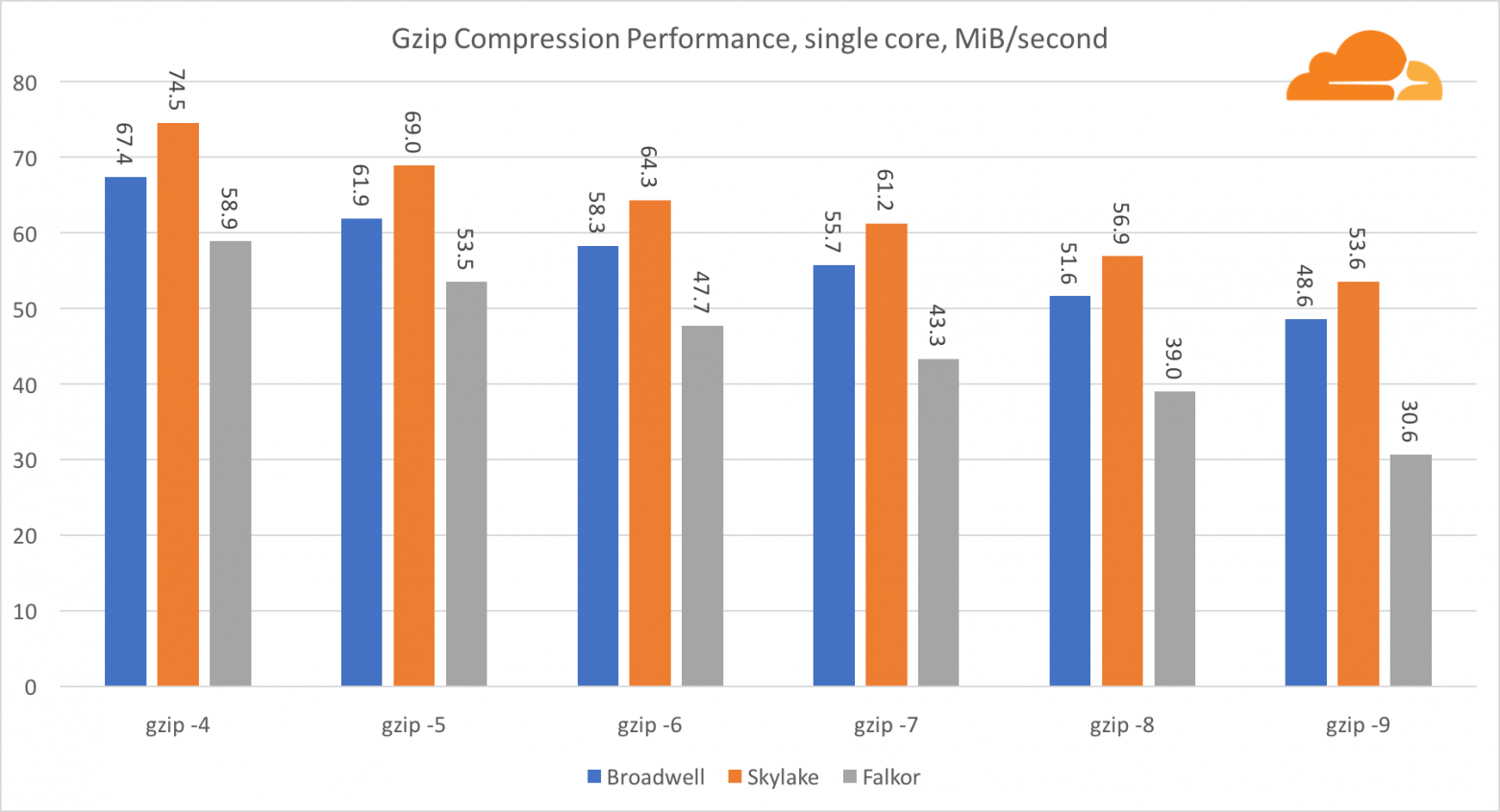
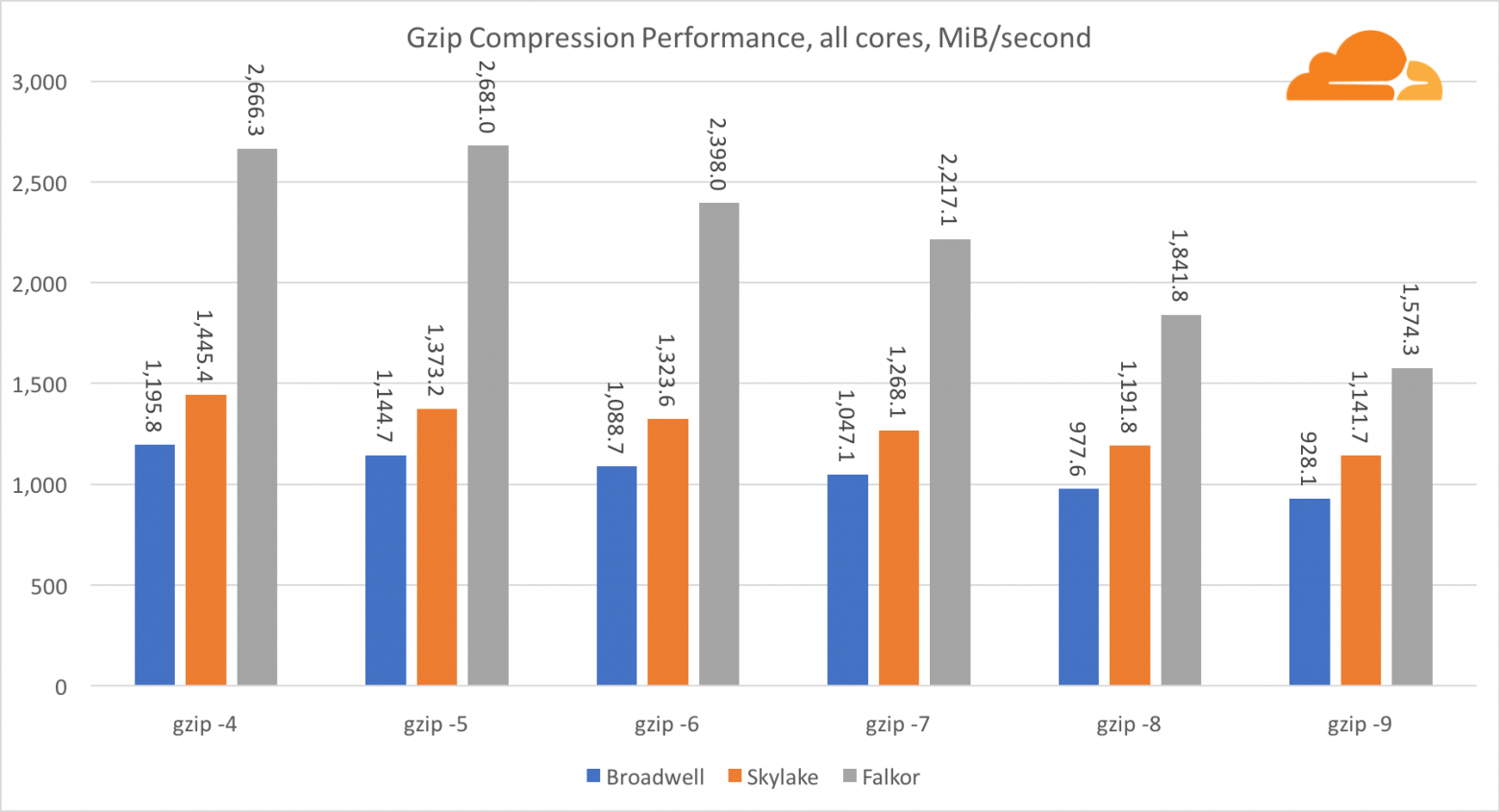
Используя gzip на уровне одного ядра, Skylake бесспорно побеждает. Имея более низкую частоту, чем Broadwell, Skylake выигрывает за счет более низкого уровня воздействия branch misprediction. Ядро Falkor не сильно отстает. На системном уровне Falkor показывает себя намного лучше, за счет большего числа ядер. Обратите внимание, насколько gzip хорошо масштабируется на нескольких ядрах.
Brotli
С brotli на одном ядре ситуация схожа с предыдущей. Skylake является самым быстрым, но Falkor не очень отстает. А на стандарте 9, Falkor даже быстрее. Brotli со стандартом 4 очень похож на gzip уровня 5, в то время как фактическая компрессия все же лучше (8010B против 8187B).
Пр компрессии на нескольких ядрах, ситуация становится немного запутанной. Для уровней 4, 5 и 6 brotli скейлится очень хорошо. На уровне 7 и 8 производительно на ядро начинает падать, опускаясь до дна на уровне 9, где мы получаем в 3 раза меньше производительность работы всех ядер в сравнении с одним.
По моему представлению, это связано с тем что с каждым уровнем brotli начинает потреблять больше памяти и рушит кэш. Показатели начинают восстанавливаться уже на уровне 10 и 11.
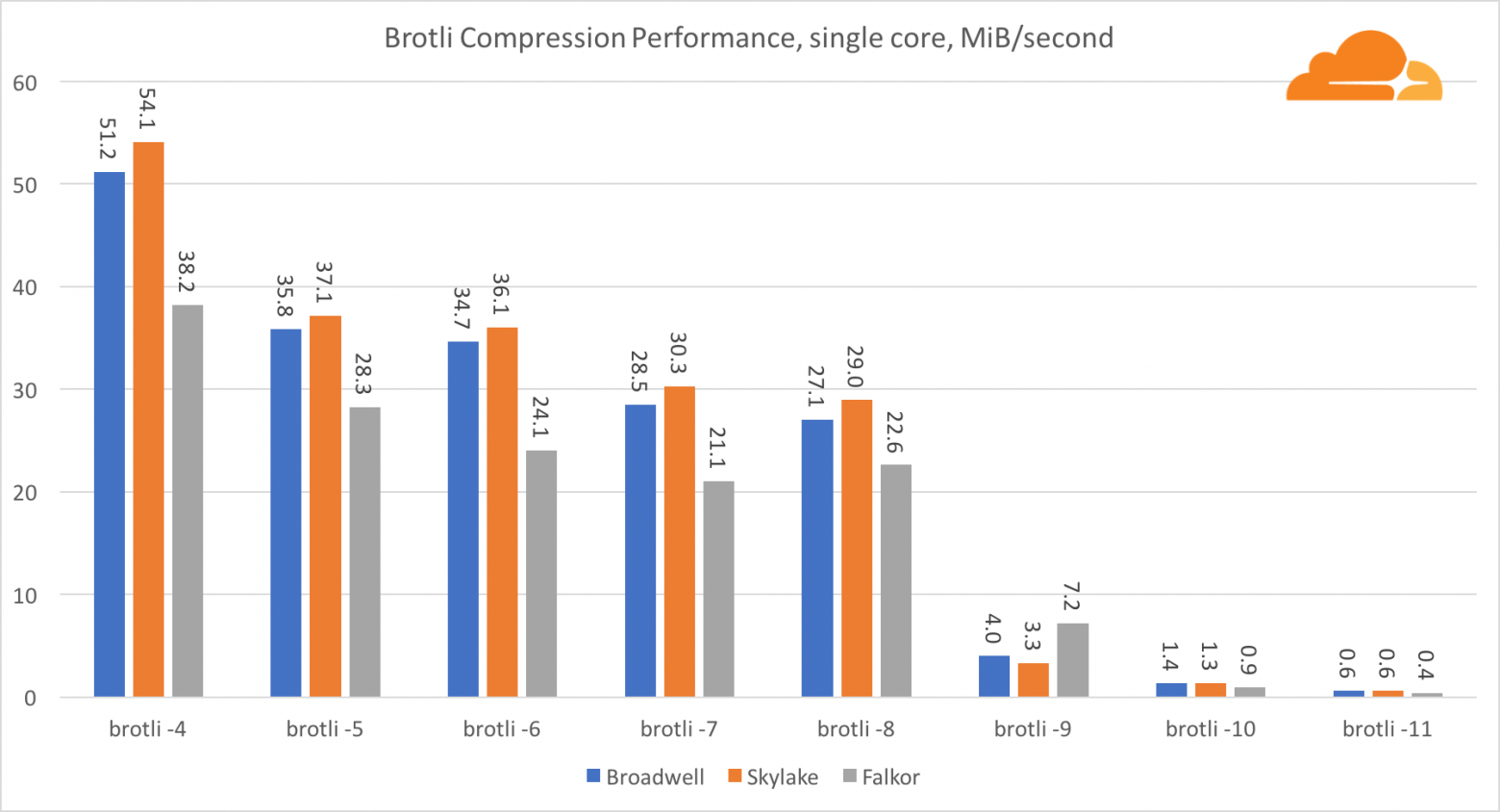

Как вывод — победу одержал Falkor, учитывая что динамическое сжатие не перейдет выше 7 уровня.
Golang
Golang это еще один очень важный язык для Cloudflare. Это также один из первых языков поддерживающий ARMv8, поэтому можно ожидать хорошей производительности. Я использовал некоторые встроенные тесты, но модифицировал их под множественные goroutines.
Go crypto
Я бы хотел начать с тестов производительности шифрования. Благорадя OpenSSL у нас есть отличные исходные данные, и будет весьма интересно увидеть насколько хороша библиотека Go.
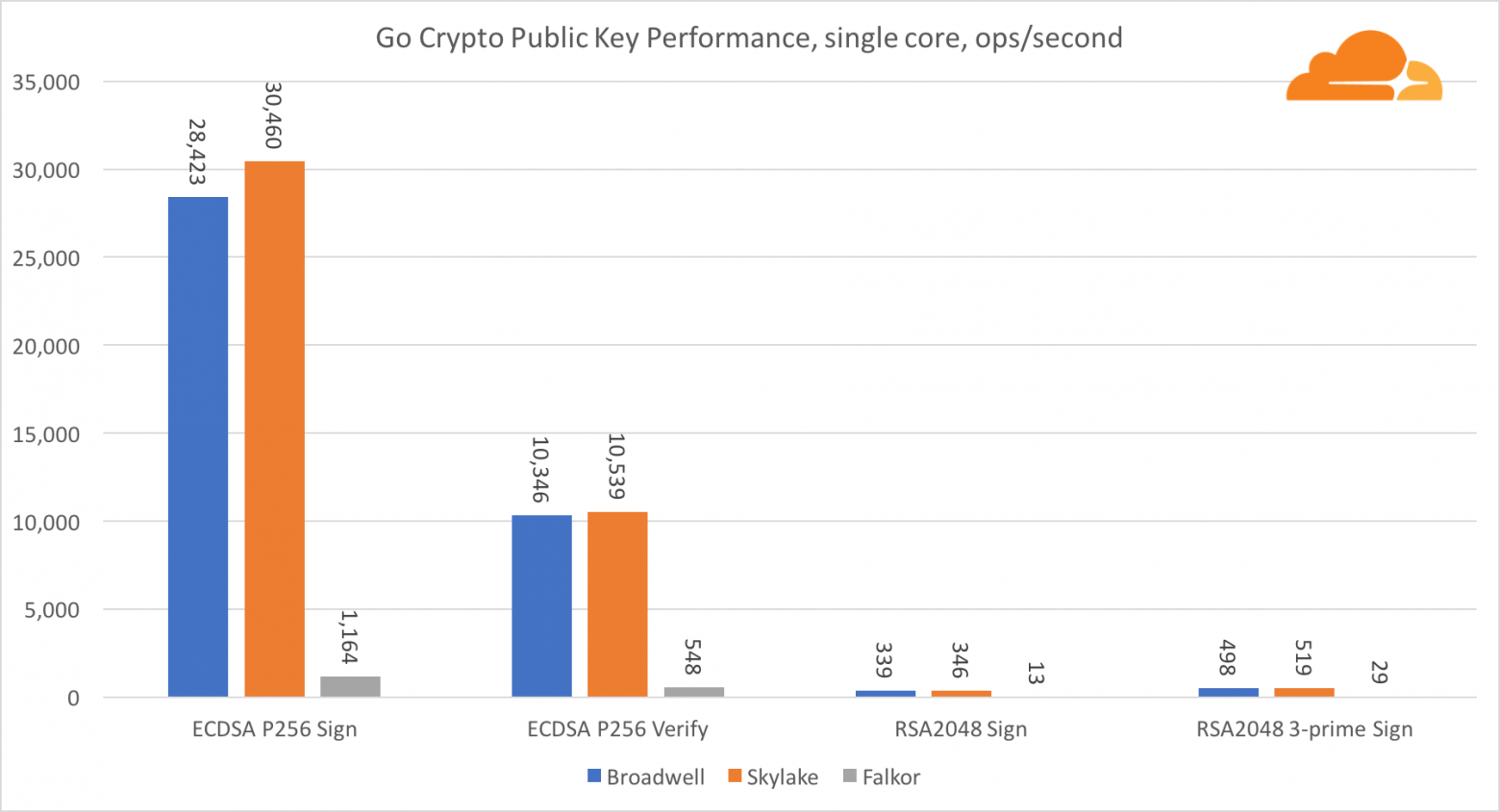
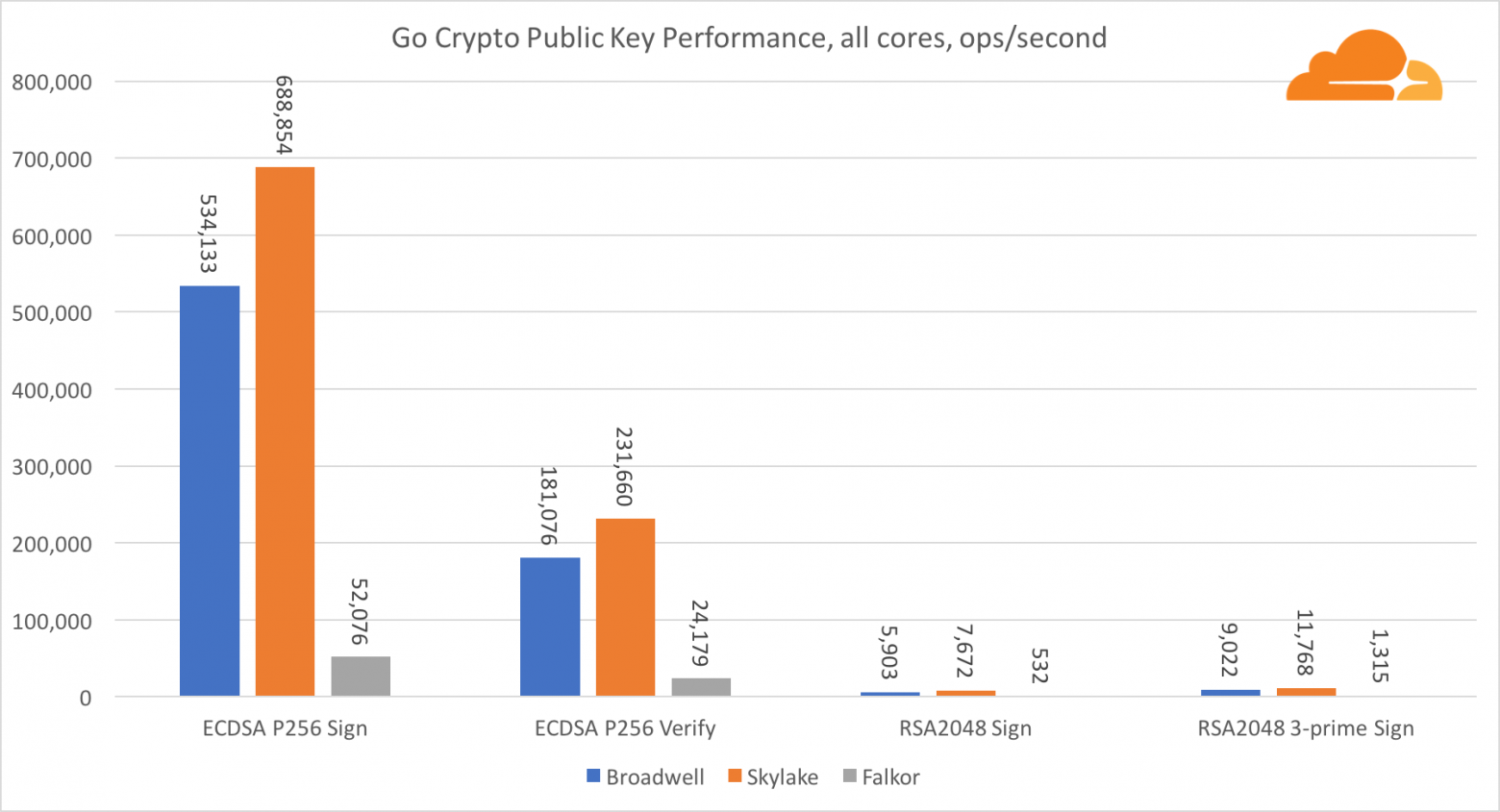
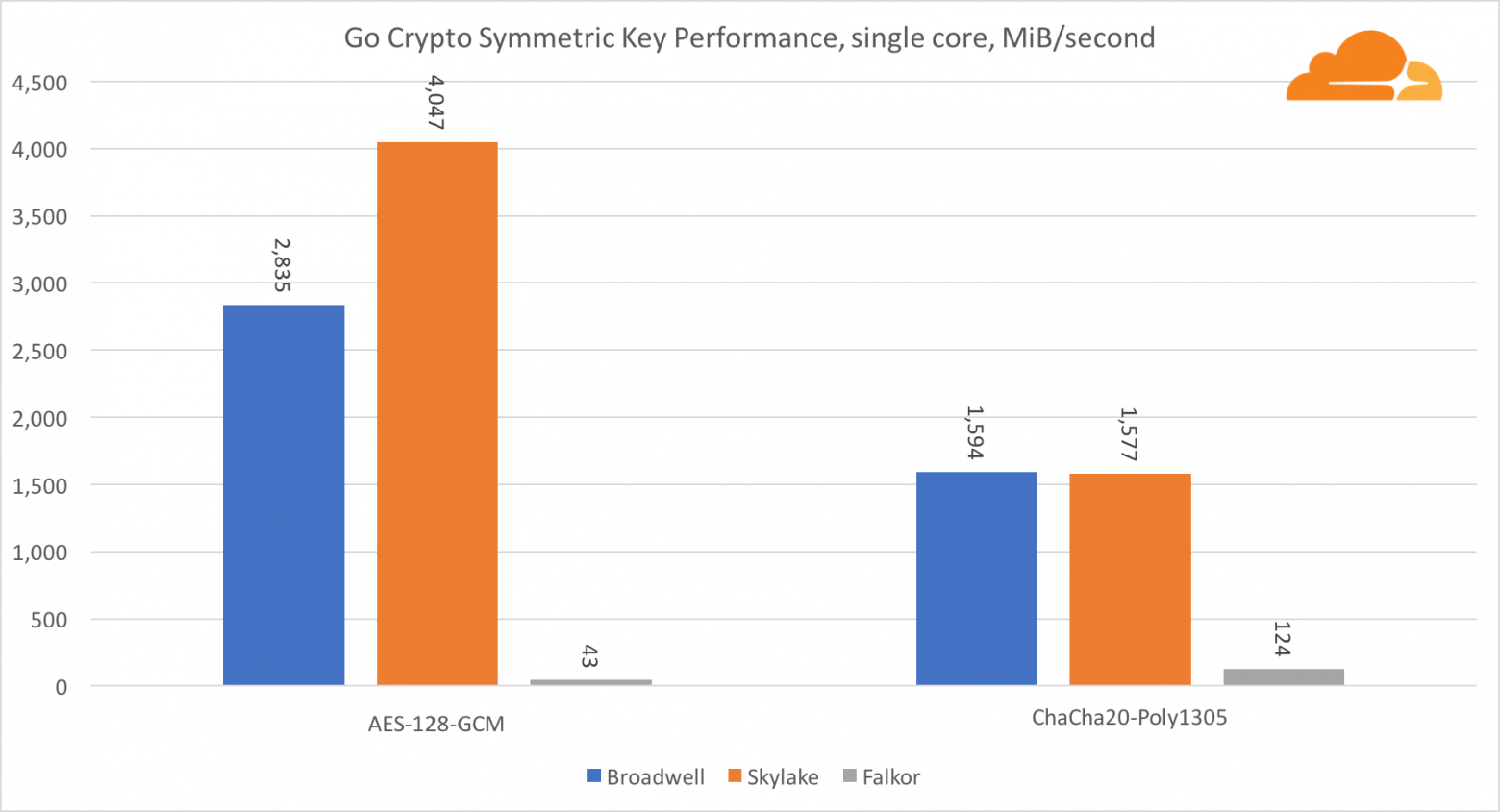
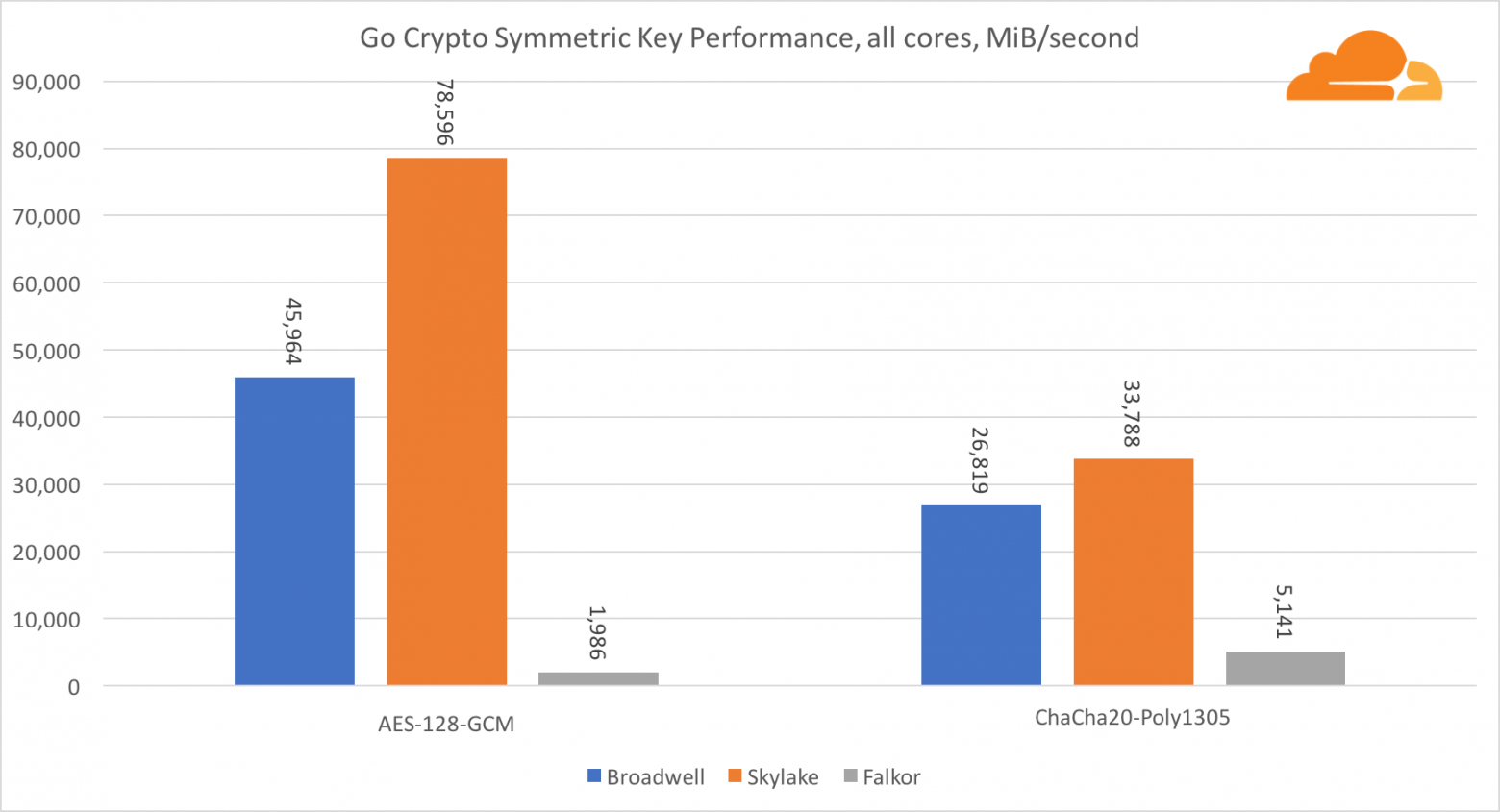
Касательно Go crypto, то ARM и Intel находятся даже не в одной весовой категории. У Go есть отлично оптимизированный ассемблерный код для ECDSA, AES-GCM и Chacha20-Poly1305 на Intel. Также есть оптимизированные математические функции, используемые в вычислениях RSA. У ARMv8 всего этого нет, что ставит его в очень невыгодное положение.
Тем не менее, разрыв можно сократить относительно небольшими усилиями, и мы знаем, что при правильной оптимизации производительность может быть на одном уровне с OpenSSL. Даже очень незначительные изменения, такие как реализация функции addMulVVW в сборке, приводят к более чем десятикратному увеличению производительности RSA, помещая Falkor (с показателем в 8009) выше как Broadwell, так и Skylake.
Стоит отметить еще одну интересную штуку — на Skylake код Go Chacha20-Poly1305, который использует AVX2, работает примерно так же как и код OpenSSL AVX512. Опять же это связано с тем, что AVX2 работает на более высоких тактовых частотах.
Go gzip
Теперь рассмотрим производительность Go со стороны gzip. Тут также есть отличный ориентир на довольно хорошо оптимизированный код, и мы можем сравнить его с Go. В случае библиотеки gzip, специфических оптимизаций для Intel нет.
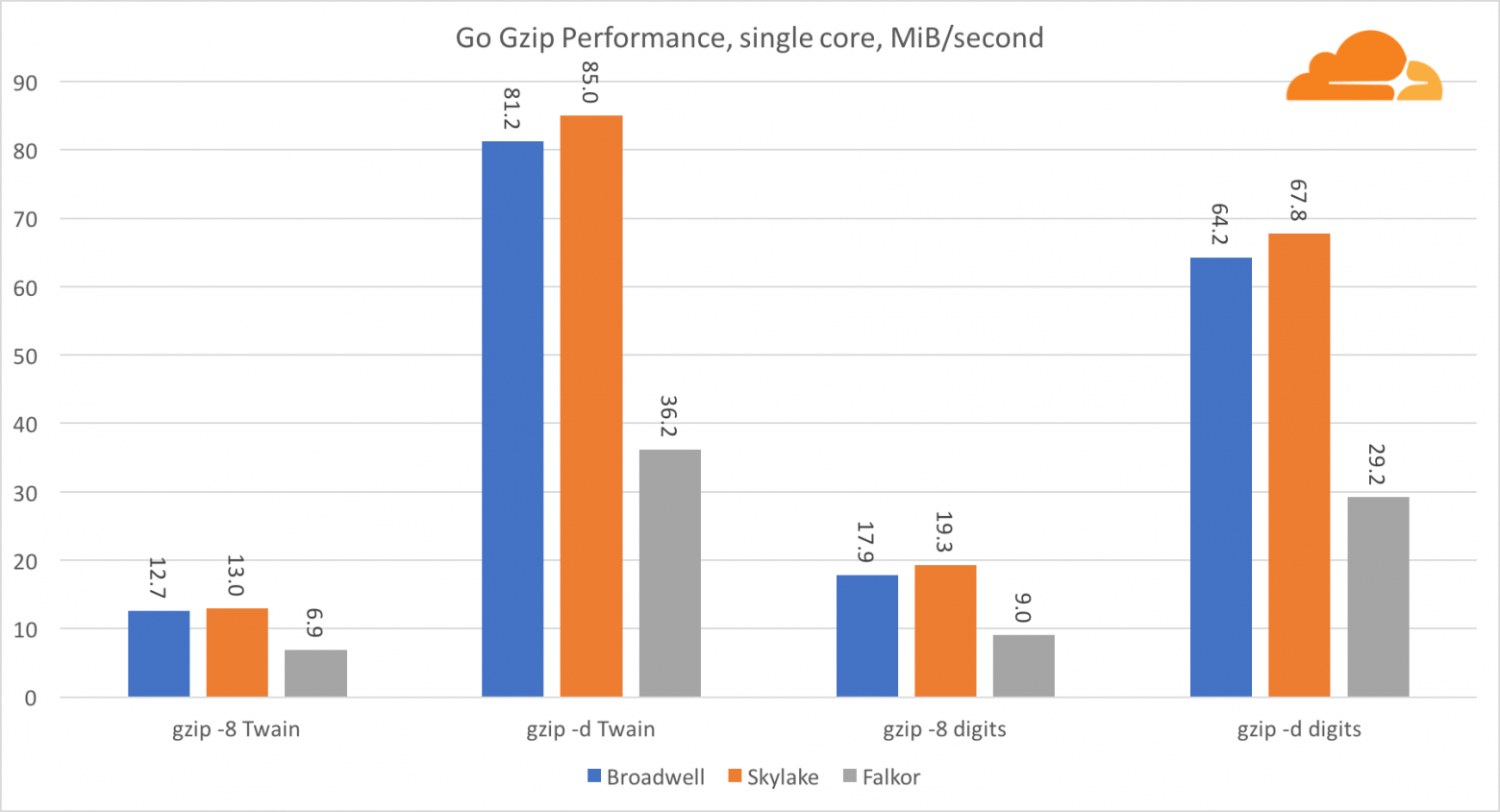
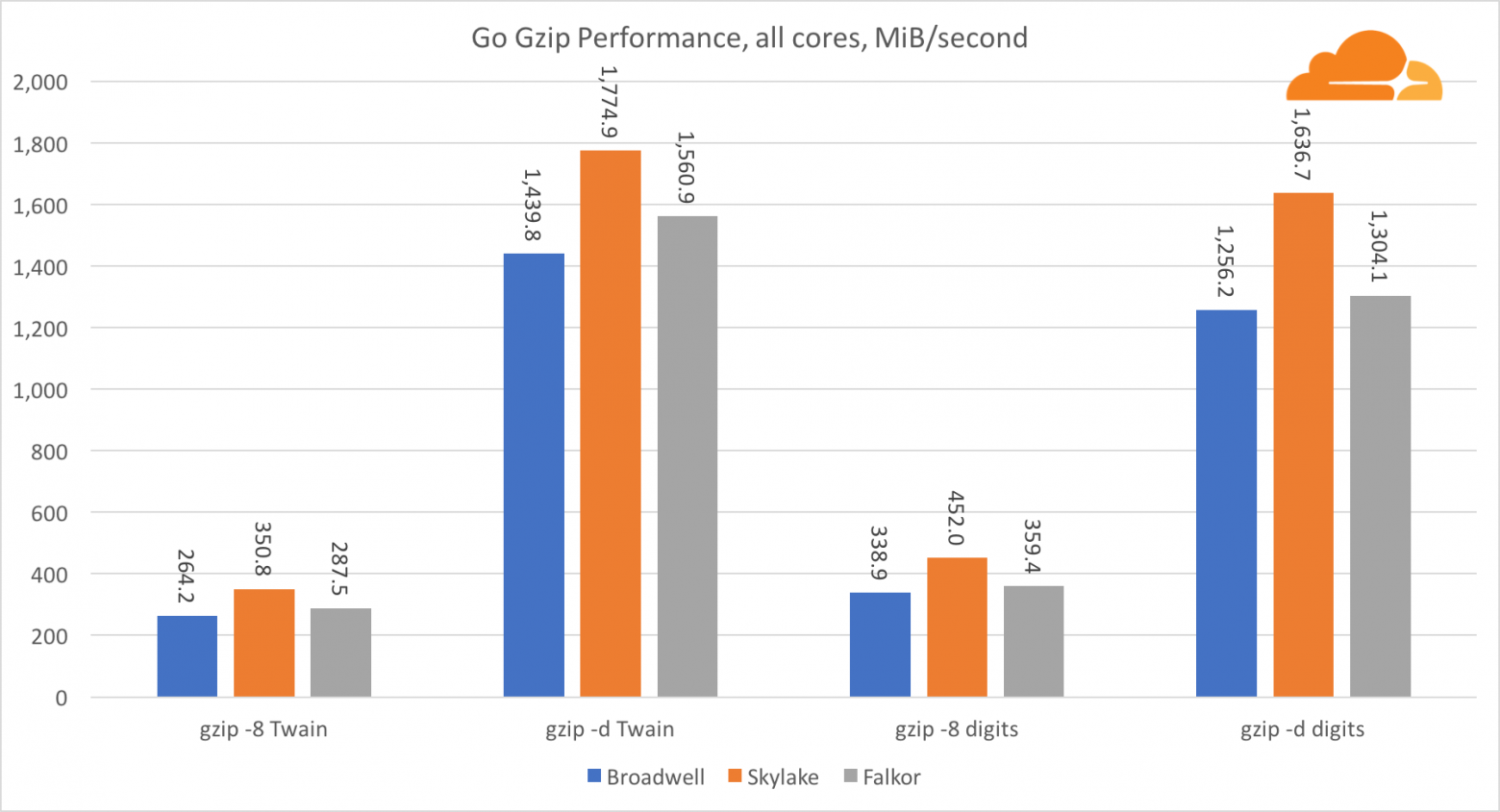
Производительность gzip довольно хороша. Производительность по одному ядру Falkor значительно отстает от обоих процессоров Intel, но на системном уровне ему удалось превзойти Broadwell и расположиться ниже Skylake. Поскольку мы уже знаем, что Falkor превосходит другие два процессора, когда работает С. Это может означать только одно — бэкенд Go для ARMv8 все еще не доработан по сравнению с gcc.
Go regexp
Regexp широко используется в самых разных задачах, потому его производительность также крайне важна. Я запустил встроенные тесты на 32 Кб потоках.
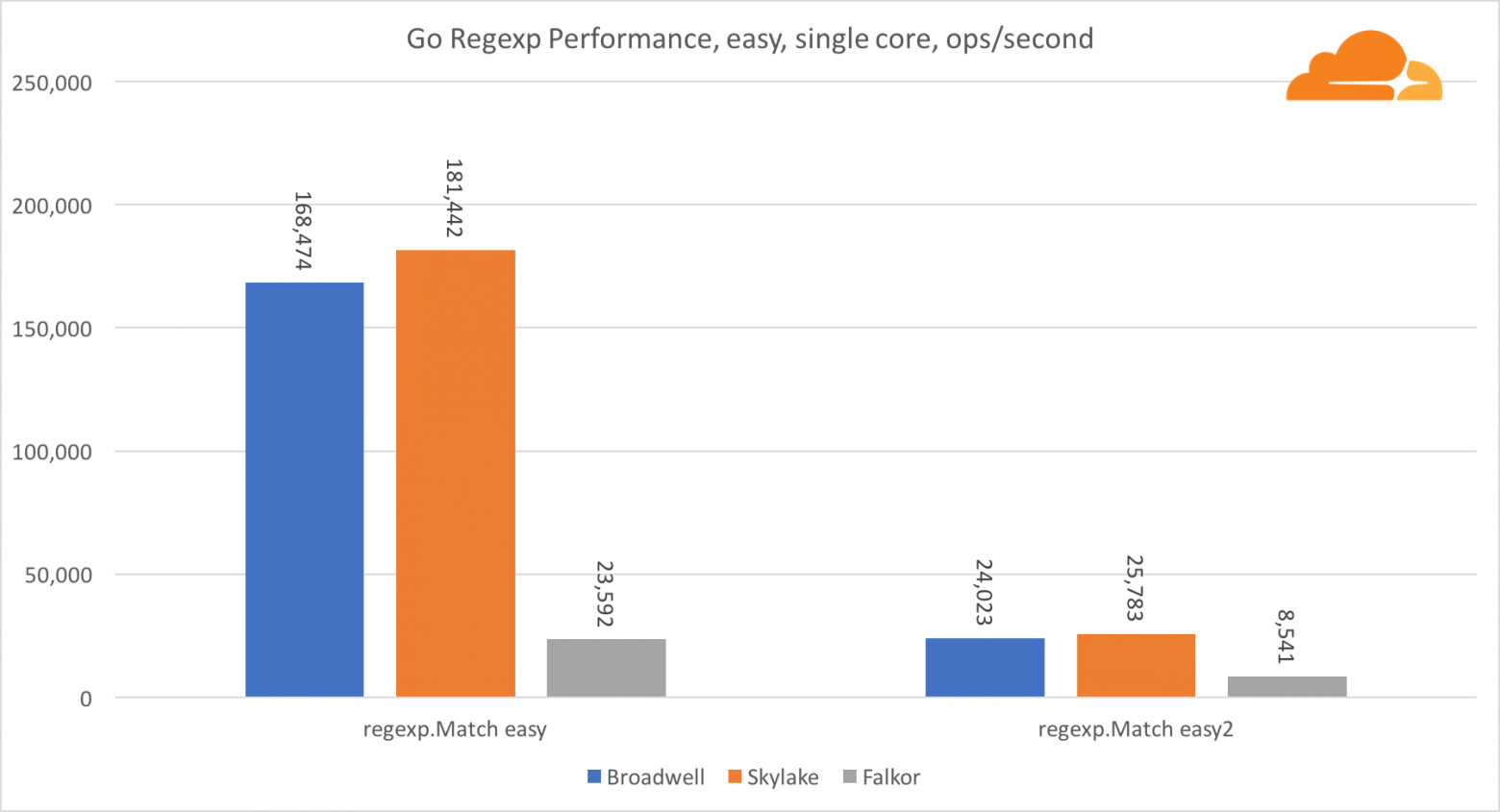
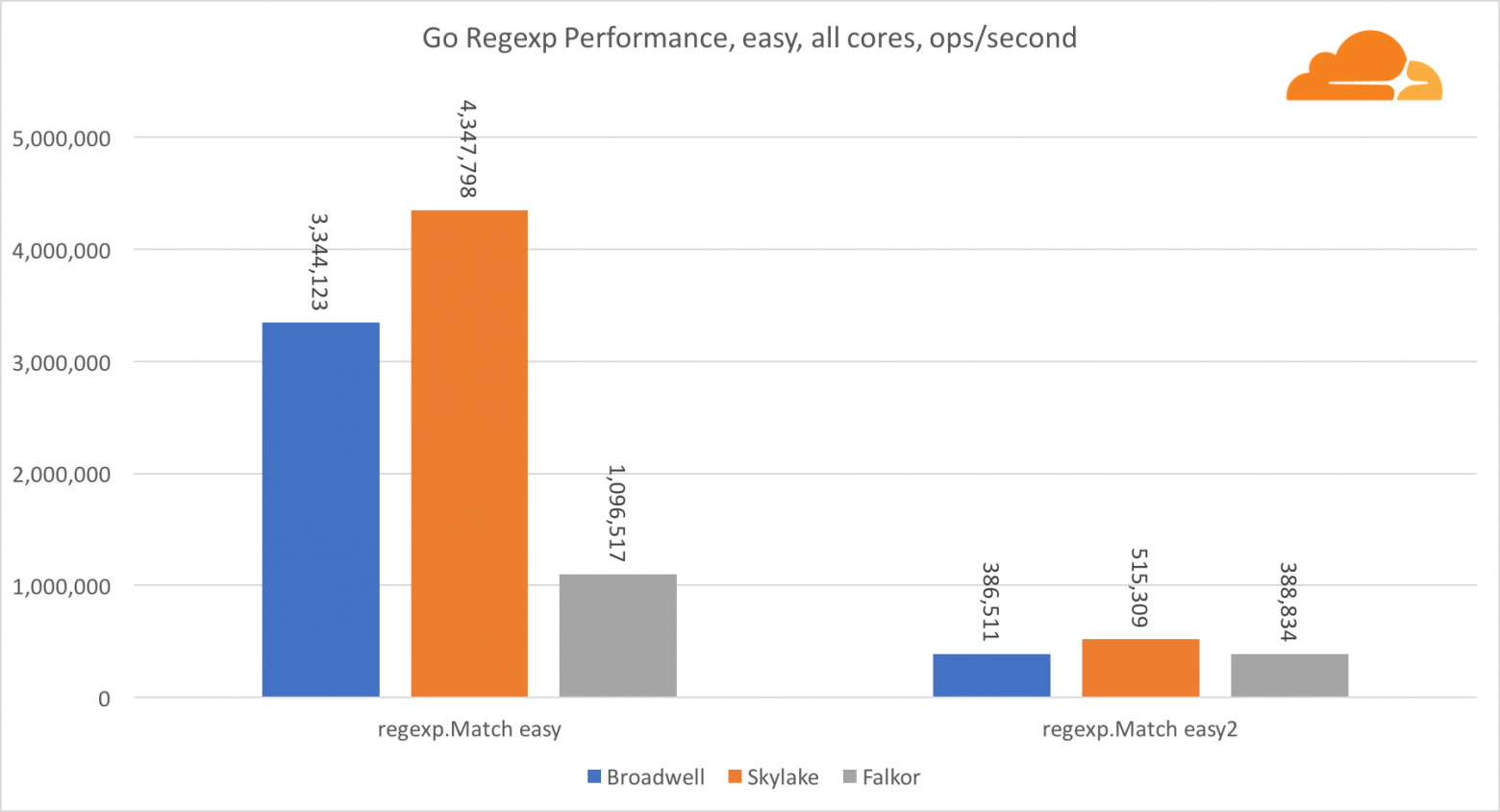
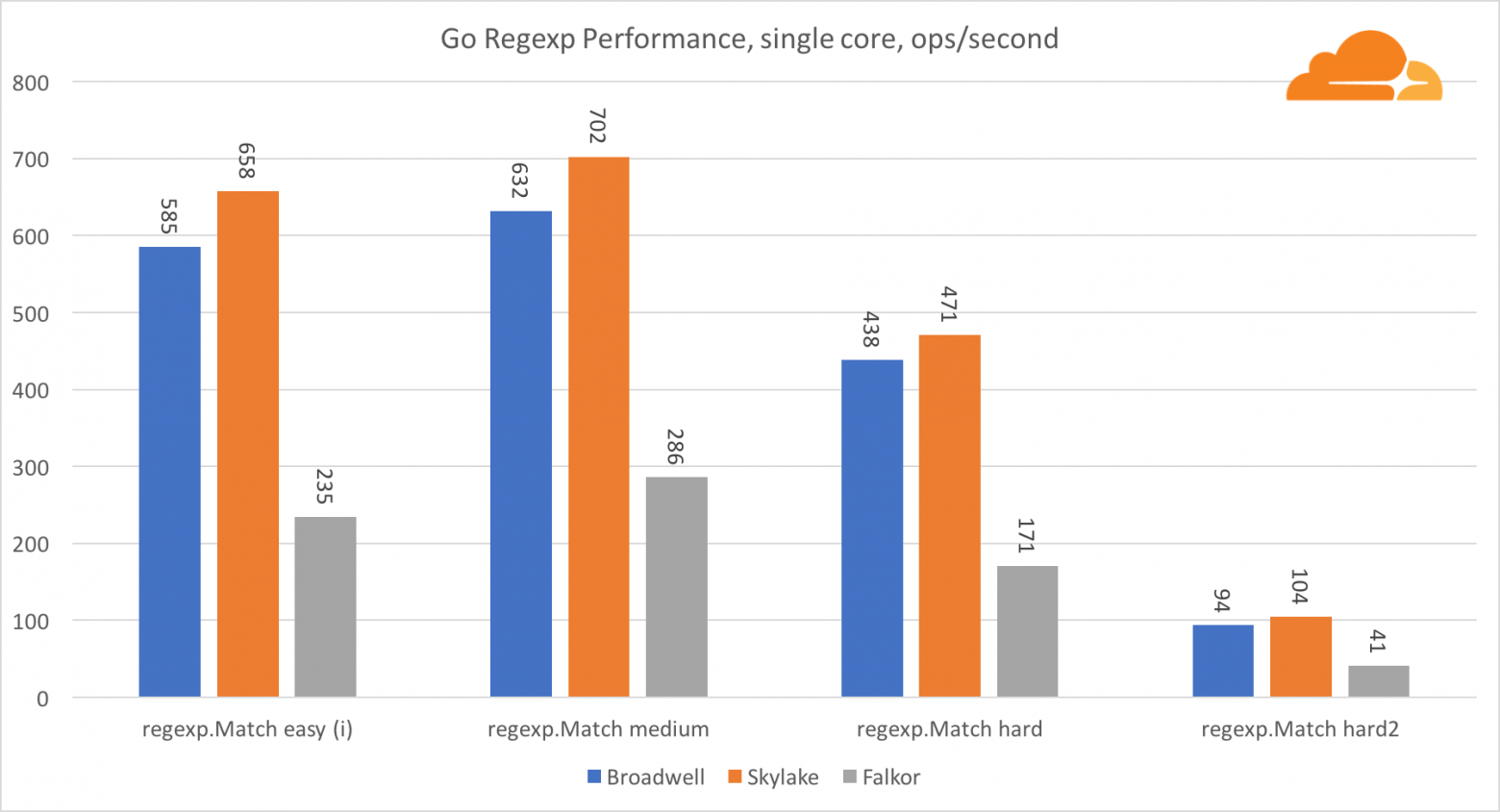
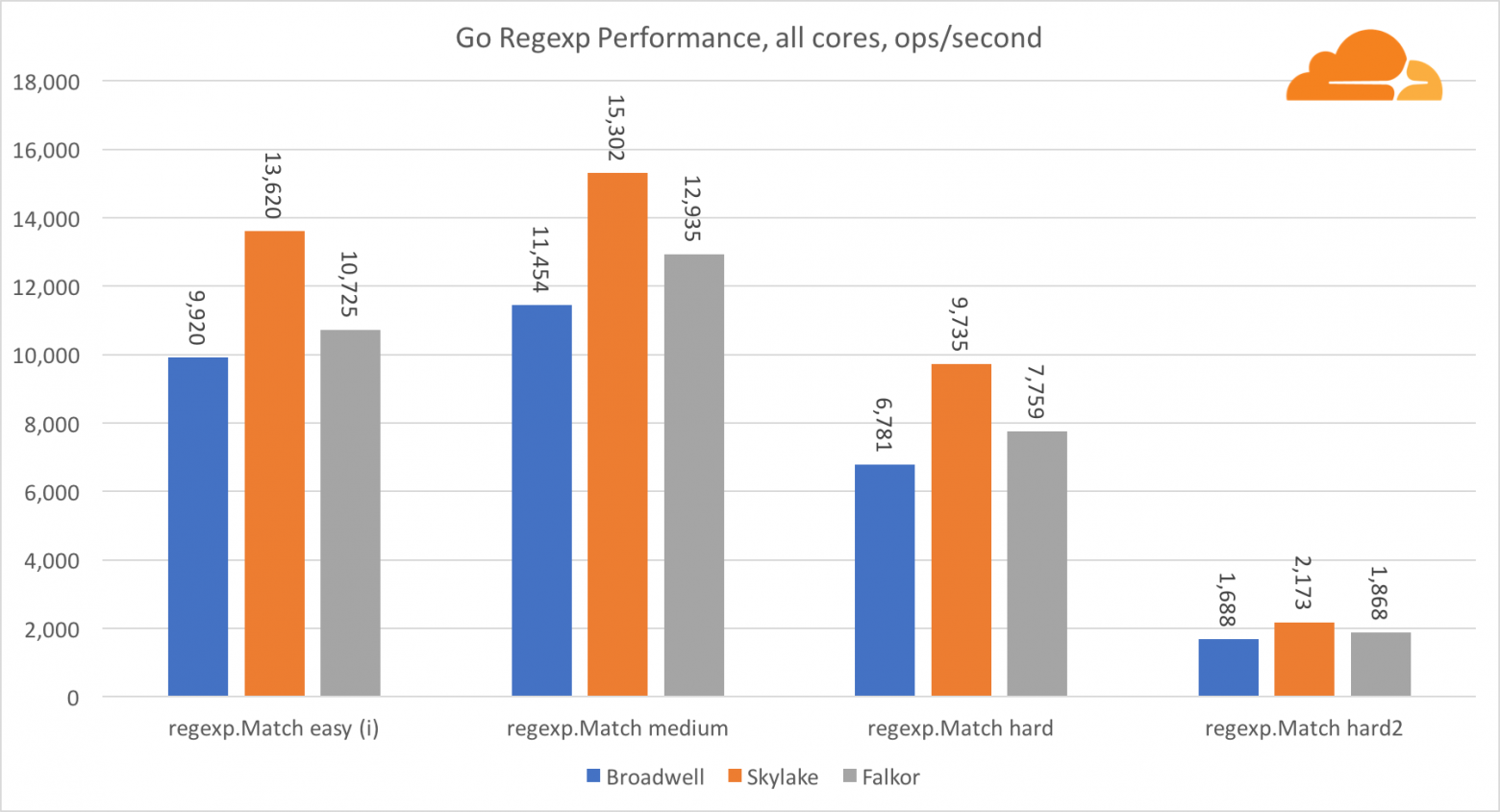
На Falkor производительность Go regexp не очень хороша. На средних и сложных тестах он занимает второе место, благодаря большему числу ядер, но, все же, Skylake значительно быстрее.
Более подробное рассмотрение процесса показывает, что много времени тратится на функцию bytes.IndexByte. Эта функция обладает ассемблер реализацией для amd64 (runtime.indexbytebody), но основная реализация для Go. Во время легких тестов regexp еще больше времени проводилось в этой функции, что объясняет еще больший разрыв.
Go strings
Еще одна важная для веб-сервера библиотека это Go strings. Я тестировал только основной Replacer class.
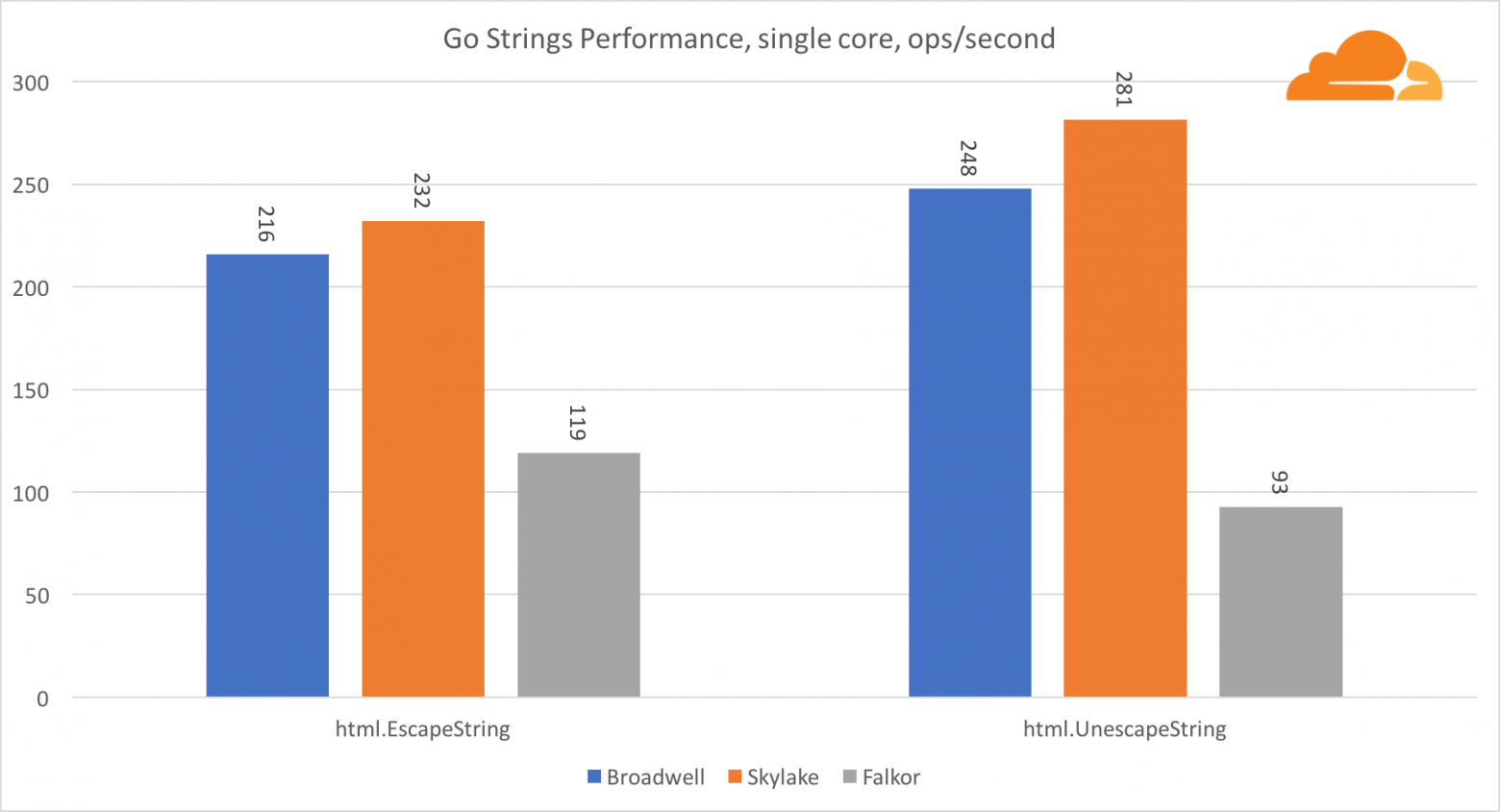
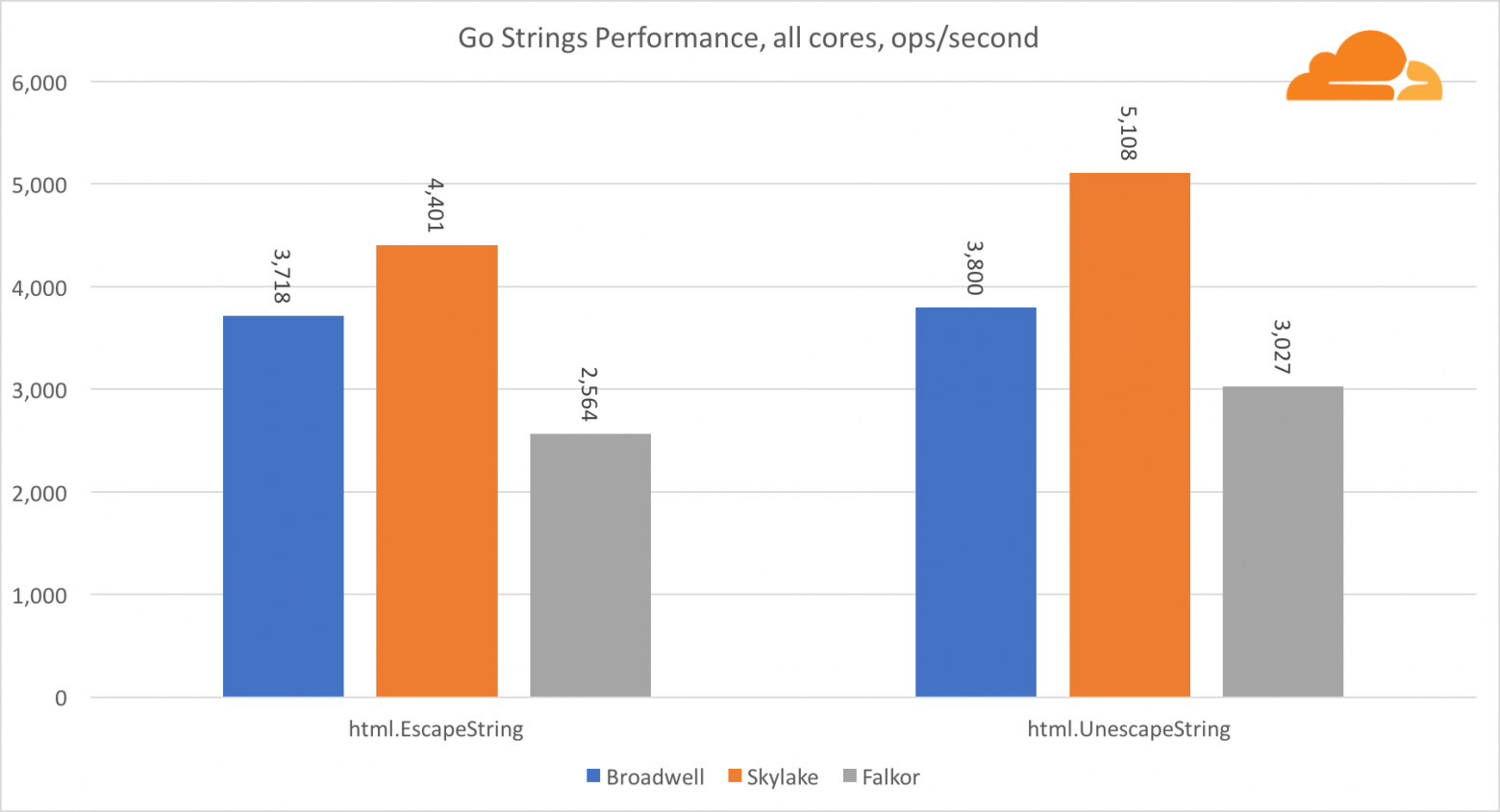
В этом тесте Falkor опять отстает, уступая даже Broadwell. Подробное рассмотрение показывает долгое пребывание в функции runtime.memmove. Знаете что? У нее есть отлично оптимизированный код ассемблера для amd64, который использует AVX2, но только самый простой ассемблер, который копирует 8 байт за один раз. Изменив 3 строчки в этом коде и использовав инструкции LDP/STP (загрузка пары / хранение пары) можно копировать единовременно 16 байт, что увеличило производительность memmove на 30%, что, в свою очередь, на 20% ускоряет работу EscapeString и UnescapeString. И это только верхушка айсберга.
Вывод по Go
Поддержка Go на aarch64 довольно разочаровывающая. Я с радостью заявляю, что все компилировалось и работало безукоризненно, но со стороны производительности могло быть и лучше. Складывается впечатление, что большая часть усилий была потрачена на бэкэнд компилятора, а библиотека была практически нетронута. Существует множество низкоуровневых оптимизаций, к примеру мое исправление addMulVVW, которое заняло 20 минут. Qualcomm и другие поставщики ARMv8 намерены потратить значительные технические ресурсы на исправление ситуации, но любой, на самом деле, может внести свой вклад в Go. Поэтому, если вы хотите оставить свой след в истории, сейчас самое время.
LuaJIT
Lua это клей, который скрепляет воедино Cloudflare.
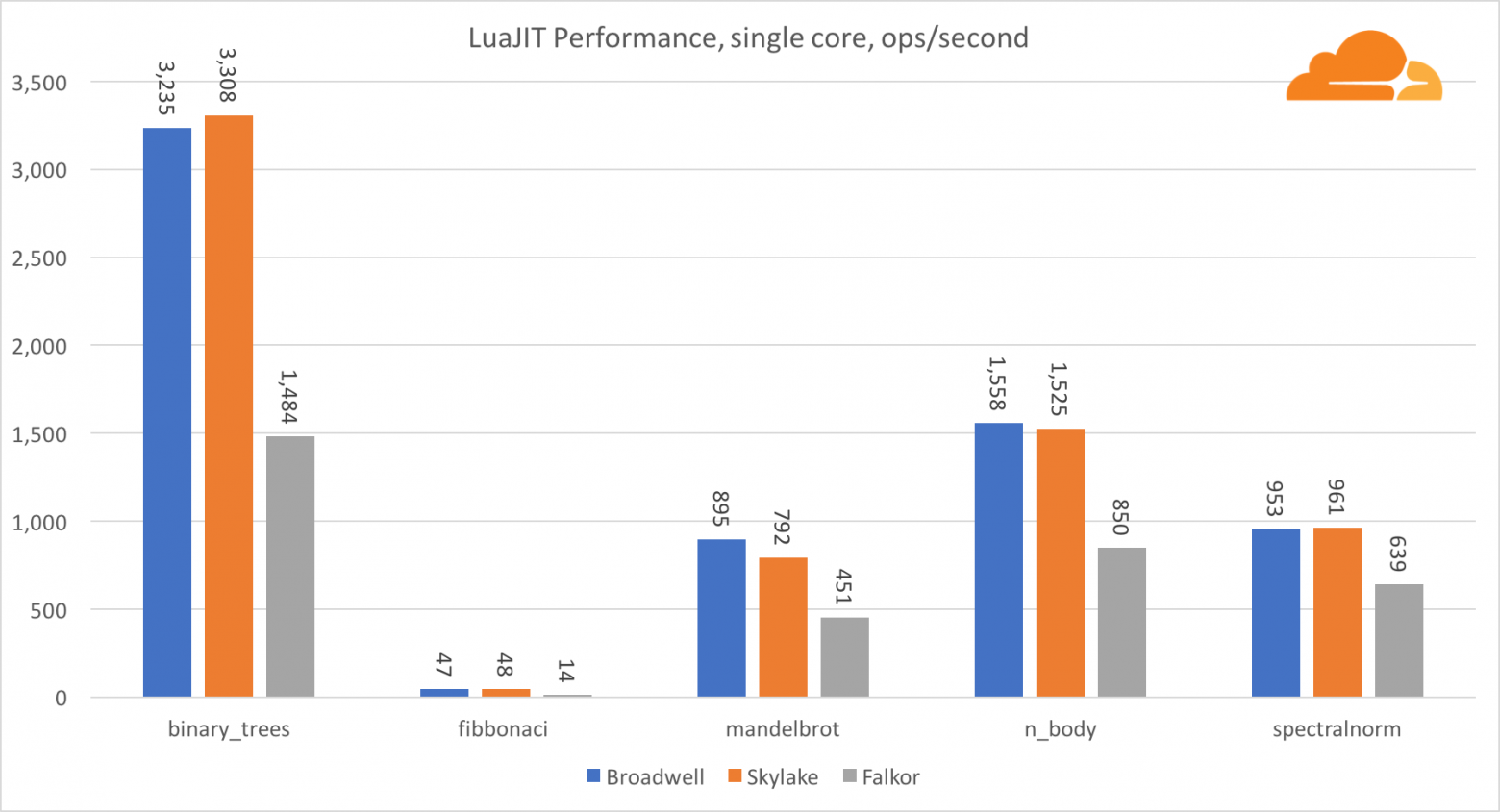
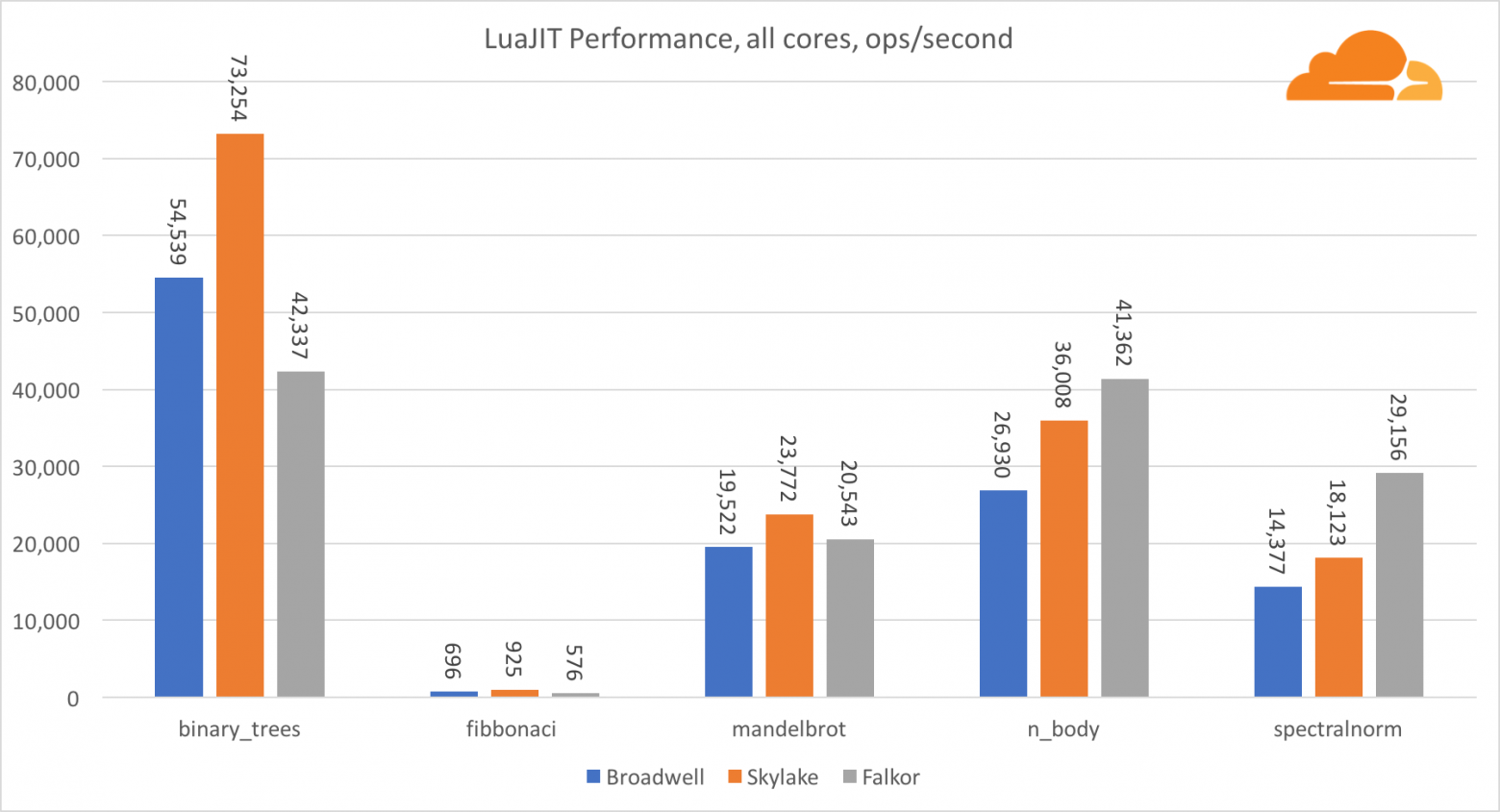
За исключением теста binary_trees, производительность LuaJIT на ARM очень конкурентоспособна. Два теста он выигрывает, а на третьем идет нос в нос с конкурентами.
Стоит заметить, что тест binary_trees крайне важен, поскольку в нем задействовано множество циклов распределения памяти и сбора мусора. Он требует более дотошного рассмотрения в будущем.
NGINX
В качестве рабочей нагрузки NGINX я решил создать таковую, которая будет напоминать фактический сервер.
Я настроил сервер, который обслуживает HTML-файл, используемый в тесте gzip, поверх https, с помощью набора шифров ECDHE-ECDSA-AES128-GCM-SHA256.
Он также использует LuaJIT для перенаправления входящего запроса, удаления всех разрывов строк и дополнительных пробелов из файла HTML при добавлении метки времени. Затем HTML сжимается с использованием brotli 5.
Каждый сервер был настроен для работы с таким количеством пользователей, как у виртуальных процессоров. 40 для Broadwell, 48 для Skylake и 46 для Falkor.
В качестве клиента для этого теста я использовал программу hey, работающую от 3 серверов Broadwell.
Одновременно с тестом мы взяли показания мощности из соответствующих блоков BMC каждого сервера.
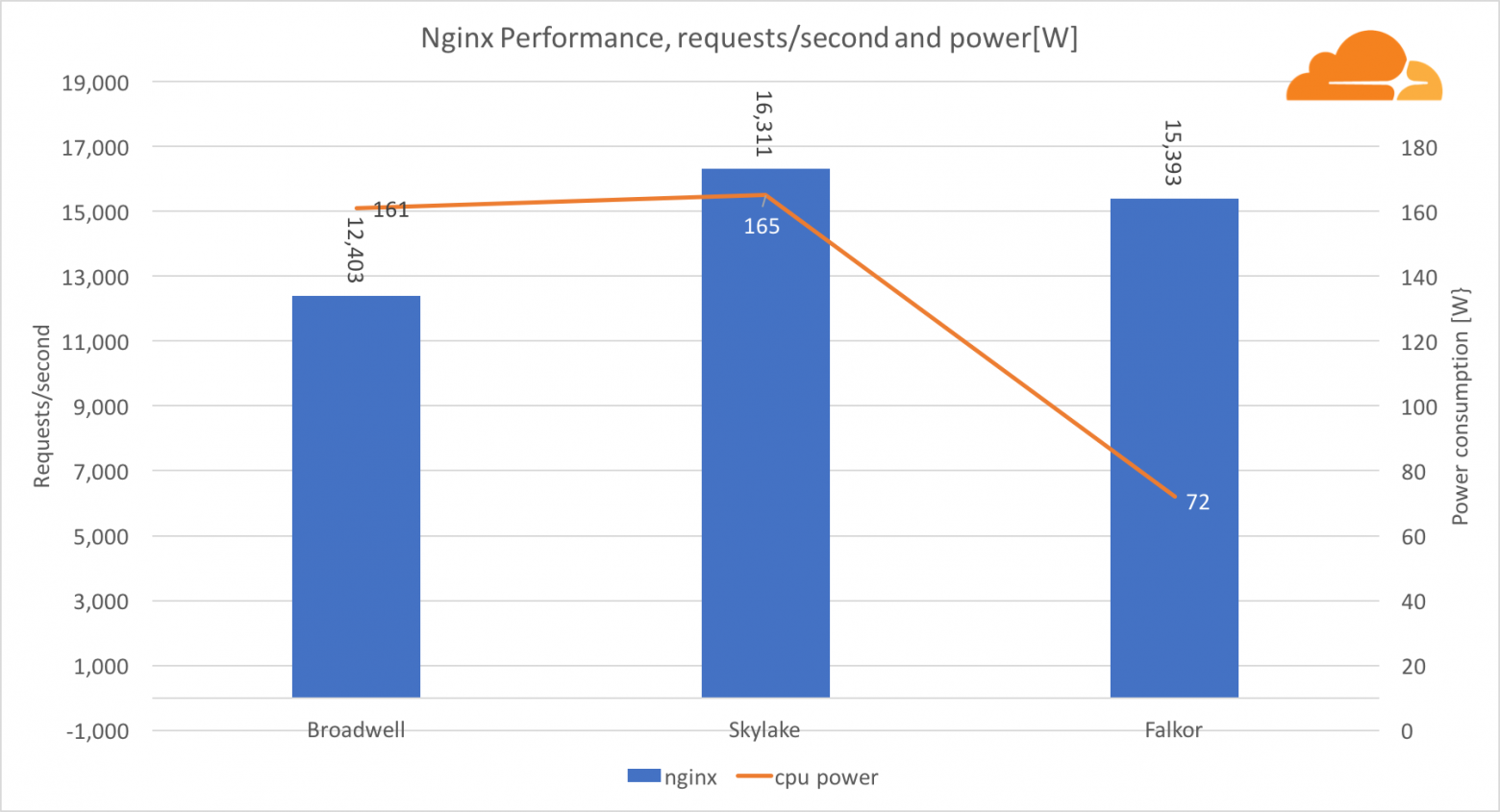
С рабочей нагрузкой NGINX Falkor обрабатывал почти то же количество запросов, что и сервер Skylake, и оба они значительно опережают Broadwell. Показания мощности, взятые из BMC, показывают, что это происходило при потреблении мощности в половину меньше, чем другие процессоры. Это означает, что Falkor удалось получить 214 запросов/Вт, Skylake — 99 запросов/Вт и Broadwell — 77 запросов/Вт.
Я был удивлен тем, что Skylake и Broadwell потребляют примерно одинаковый объем энергии, при учете того, что производятся они одинаково, а у Skylake больше ядер.
Низкое потребление энергии у Falkor не удивляет, так как процессоры от Qualcomm известны своей высокой энергоэффективностью, что позволило им занять доминирующее положение на рынке процессоров для мобильных устройств.
Заключение
Образец Falkor, который мы получили, меня действительно поразил. Это огромный шаг вперед, по сравнению с предыдущими попытками в серверах на базе ARM. Конечно сравнивая ядро с ядром, Intel Skylake значительно лучше, но если рассматривать системный уровень, производительность становится весьма привлекательной.
Производственная версия Centriq SoC будет содержать 48 Falkor ядер, работающих на частоте до 2.6 Ггц, что дает потенциальный рост производительности в 8%.
Очевидно, что тестируемый нами Skylake не является флагманом, как Platinum с его 28 ядрами, но эти 28 ядер стоят много и потребляют 200W, в то время как мы стараемся оптимизировать наши затраты и увеличить производительность на 1 ватт.
На данный момент меня больше всего беспокоит плохая производительность языка Go, но это измениться как только сервера на базе ARM займут свою нишу на рынке.
Производительность С и LuaJIT очень конкурентоспособна, и во многих случаях превосходит Skylake. Практически во всех тестах Falkor показал себя как достойная замена Broadwell.
Самым большим плюсом для Falkor на данный момент остается низкий уровень энергопотребления. Хотя TDP и составляет 120W, во время моих тестов этот показатель никогда не превышал 89W (для тестов go). Для сравнения, Skylake и Broadwell превысили отметку в 160W, тогда как их TDP составляет 170W.
На правах рекламы.Это не просто виртуальные серверы! Это VPS (KVM) с выделенными накопителями, которые могут быть не хуже выделенных серверов, а в большинстве случаев — лучше! Мы сделали VPS (KVM) c выделенными накопителями в Нидерландах и США (конфигурации от VPS (KVM) — E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD или 4TB HDD / 1Gbps 10TB доступными по уникально низкой цене — от $29 / месяц, доступны варианты с RAID1 и RAID10), не упустите шанс оформить заказ на новый тип виртуального сервера, где все ресурсы принадлежат Вам, как на выделенном, а цена значительно ниже, при гораздо более производительном «железе»!
Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки? Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США!
