
Количество американских патентных заявок связанных с социальными сетями последние 5 лет росло на 250% каждый год (ссылка). Так, например, одна корпорация подала патентную заявку на метод ценообразования который учитывает положение покупателя в социальном графе (обсуждение на Slashdot). Другая корпорация недавно воплотила максимально упрощенный вариант этой схемы, продавая свои новые телефоны влиятельным узлам социального графа за $0, а остальным за $530.
Анализ социальных сетей (Social Network Analysis) существовал задолго до Интернета, но в последнее время набирает обороты.
Мне было интересно посмотреть, как эффективно алгоритм, выделяющий кластеры в графах, сработает для некоторых групп в Twitter, которые представляют для меня интерес.
23 января в Запорожье пройдет #UKRTWEET — первый всеукраинский баркэмп посвященный Twitter. Граф выше показывает, кто из его участников, с кем разговаривает и кого упоминает.
Заметка ниже посвящена анализу этого графа. Весь код используемых здесь скриптов лежит на github. Изложение, в какой-то мере, вдохновлено недавно упомянутой на Хабре книгой Тоби Сегаран «Программируем коллективный разум», код примеров которой доступен на сайте автора.
Также о data mining в Twitter я говорил 16 января на первой в этом году донецкой встрече "Кофе и код". Поэтому здесь параллельно проведу анализ группы людей из Донецка, которые пишут в Twitter. Кстати, в этом году донецкие встречи будут регулярными — каждую третью субботу месяца (следующая 20 февраля). Следите за группой.
1. Получение информации
Для начала, получаем список всех участников групп. Список участников #UKRTWEET есть на странице баркэмпа. Скачиваем и парсим его при помощи BeautifulSoup (код). Для людей, которые твитят из Донецка, я веду список @dudarev/donetsk. Сохраняем его участников при помощи библиотеки tweepy (код).
Для каждого из участников скачиваем последние 100 твитов и сохраняем их. Tweepy автоматически парсит JSON, а так как в этот раз мы хотим сохранить данные такими какие они есть, то немного подправляем класс tweepy.API (код).
2. О чем говорят
Теперь можно анализировать информацию. И сначала — пара наблюдений не связанных с социальным графом. Давайте посмотрим какие хэштеги наиболее часто употреблялись каждой группой. Для этого напишем утилиту, которая принимая строку возвращает список всех встречающихся в ней хэштегов. Для ее написания TDD — весьма кстати (смотрим код). С помощью этой утилиты парсим все твиты (код).
Наиболее часто-упоминаемые хэштеги участниками #UKRTWEET (число в скобках — количество разных людей, которые использовали этот хэштег):
- ukrtweet (20)
- sledui (20)
- elect_ua (16)
- ru_ff (10)
- zp_ua (9)
- nicua (9)
- google (9)
- twitter (7)
- habr (7)
Люди из Донецка упоминали:
- donetsk (31)
- habr (12)
- radiot (8)
- sledui (7)
- ru_ff (7)
- google (7)
- wave (6)
- linux (6)
Как видим, в каждой группе, хэштег, описывающий группу — на первом месте по употреблению. Есть и общие интересы: habr, ru_ff, sledui, google.
3. Когда говорят
Давайте посмотрим, в какое время, группа проявляет наибольшую активность. Для этого воспользуемся тем же самым скриптом, пробегающим по всем твитам, но на этот раз сформируем списки количества твитов в данный час дня и сохраним их в отдельных файлах (опция '-t' при вызове из коммандной строки). Изобразим диаграмы при помощи библиотеки Matplotlib (код).
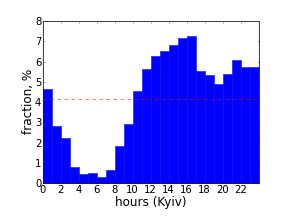
Участники #UKRTWEET проявляют активность выше средней с 10 утра до 1 часа ночи по киевскому времени, с пиком около 5 часов вечера.

Дончане активны в то же время, но пик наблюдается около 11 вечера. Быть может, это потому что люди собирающиеся на баркэмп рассматривают Twitter как рабочий инструмент и активны в нем в рабочее время. Хотя, из-за недавних праздников, эти данные могут быть не показательными.
4. Социальный граф
Граф из данных Twitter можно строить различными способами. Здесь мы будем следовать следующей конструкции: если человек А упомянул человека Б хотя бы один раз (не важно ретвит или ответ), от вершины А к вершине Б строим ориентированное ребро. Граф не взвешенный, то есть ребро строим только единожды.
Все тот же скрипт с опцией '-g' выстраивает из сохраненных твитов словарь представляющий такой граф и сохраняет его в формате JSON для последующего анализа (код).
Несколько количественных наблюдений. В группе #UKRTWEET 58% упоминают кого-то из группы (61/106). А всего упоминают 1221 человека что в 11.5 раз больше самой группы (1221/106).
В донецкой же группе 51.6% вовлечены в группу (116/225), а всего различных упоминаний в 6 раза больше самой группы (1341/225). Явно, что люди, которые собираются посетить баркэмп о Twitter более активно используют его как средство общения.
5. Авторитетность
Авторитетность в социальном графе можно анализировать разными способами. Самый простой — отсортировать участников по количеству входящих ребер. У кого больше — тот больше авторитетен. Такой способ годен для небольших графов. В поиске по Интернету Google в качестве одного из критериев для авторитетности страниц использует PageRank. Он вычисляется при помощи случайного блуждания по графу, где в качестве узлов — страницы, а ребро между узлами — если одна страница ссылается на другую. Случайный блуждатель двигается по графу и время от времени перемещается на случайный узел и начинает блуждание заново. PageRank равен доли пребывания на каком-то узле за все время блуждания. Чем он больше, тем узел более авторитетен.
Здесь мы остановимся только на двух вышеупомянутых критериях. Стоит упомянуть, что при анализе социальных графов еще большое внимание уделяют различным центральностям. Их использование в качестве критерия авторитетности может иметь больший смысл для более распределенных социальных графов.
Одна из распространенных библиотек Python для работы с графами — NetworkX. Ее и будем использовать. Создав граф G, считать различные его параметры очень удобно. Так, например, чтобы посчитать PageRank всех узлов, достаточно написать:
pr = networkx.pagerank(G)
Хочется подчеркнуть, что все числа ниже — для искуственно выделенных из твиттерсферы групп. Другие участники этих групп, могут быть глобально более влиятельными и авторитетными. Числа ниже — для комуникаций внутри данных групп.
Давайте отобразим зависимость PageRank для всех узлов от количества узлов, которые на них указывают (код).

Естественно, большой авторитет у двух организаторов (@karelina и @u02). У известного украинского блогера @woofer_kyyiv авторитетность измеряемая в PageRank высока, хотя и упоминают меньше людей, но упоминают равномерно по группе (из разных сообществ). Авторитетность официального аккаунта баркэмпа (@ukrtweet) ниже при большем упоминании. Одна из интерпретаций: люди предпочитают общаться и упоминать людей. Быть может поэтому во многих официальных западных аккаунтах явно указываются имена вещающих.
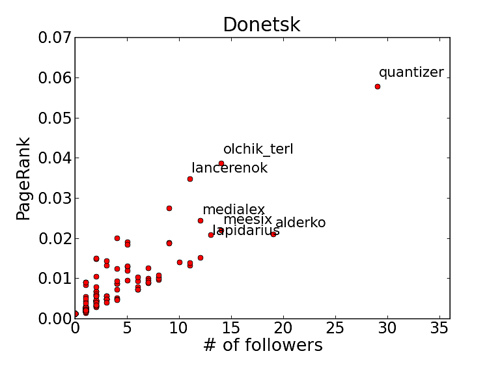
Безусловный лидер внутри донецкой группы — @quantizer. Различия в PageRank при схожих количествах упоминаний для следующих участников можно трактовать, например, так: @olchik_terl и @lancerenok больше общаются с людьми из разных частей социального графа группы, тогда как @medialex, @lapidarius, @meesix, @alderko больше взаимодействуют со своими локальными сообществами (в основном выделенными по профессиональному признаку, об этом ниже), поэтому у второй группы PageRank чуть ниже, чем у первой.
6. Влияющие извне
Люди вне групп тоже влияют на группы. Определим самых влиятельных подобно тому как делали это с хэштегами: отсортируем людей вне групп по количеству людей, которые их упоминают в группе (скрипт тот же, что парсит, но с опциями '-g -o' создает файл data/friends_outside_counts.txt).
Для #UKRTWEET (в скобках — число разных людей из группы упоминавших):
- podarok (16)
- taras (11)
- artemzeleny (11)
- blogoreader (10)
- yaroslavazhnyuk (9)
- wedmid (9)
- matteush (9)
Для Донецка:
- bobuk (12)
- olyapka (11)
- ekozlov (8)
- boomburum (7)
- abakala (7)
Такой подход можно использовать для поиска интересных людей. Если вам интересна какая-то группа, то вероятно те люди, которых эта группа упоминает, тоже могут быть вам интересны.
Как усовершенствование, можно складывать не единицы, а PageRank упоминающих. Так те, которые извне больше влияют на влиятельных в группе, будут иметь больший вес. Оставляем это для желающих в качестве упражнения с кодом.
7. Сообщества
Для алгоритмического поиска кластеров в графах наиболее популярны методы оптимизирующие модулярность. Модулярность — количественный параметр использующий количество внутренних связей внутри предполагаемых сообществ и связей с внешними сообществами. Все результаты, что будут обсуждены ниже, получены при помощи кода выложеному на сайте бельгийской группы, который они описали в статье выложенной на arxiv. Другие люди тоже выкладывали свой код для подобных целей. Также алгоритм кластеризации встроен в другую популярную библиотеку для работы с графами — igraph.
Графы с метками и сообществами отображенные с помощью Seadragon, интересного веб-приложения от Microsoft позволяющем легко выкладывать большие графические файлы в интерфейсе подобному онлайн-картам, а также одним файлом:
UkrTweet — seadragon, файл.
Донецк — seadragon, файл.
Использовались скрипт для нахождения сообществ и скрипт для рисования графа.
8. Метки для сообществ
Хотелось бы получить какую-нибудь характеристику сформировавшихся сообществ. Один из способов — посмотреть в какие списки включались люди из сообществ. Скачиваем все списки, в которые были включены люди из групп (код). Сортируем группы по суммарному PageRank и печатаем десять названий списков, которые встречались для наибольшего количества людей в группе (код). В некоторых сообществах нельзя выделить говорящие метки, но во многих метки участников о многом говорят. В таблице ниже сообщества отсортированы по суммарном PageRank, двое самых авторитетных участника, количество участников, несколько говорящих общих меток (в скобках количество человек из сообществ которые были в соответствующих списках):
UkrTweet
| Участники | Всего участников | Метки | Комментарии |
|---|---|---|---|
| u02, karelina, ... | 12 | zp-ua (10), zp (10) | Вокруг организаторов, в основном из Запорожья |
| woofer_kyyiv, gasique, ... | 12 | kyiv (8), mckyiv09 (6), bloggers (6) | Киевляне-блогеры, встречавшиеся на Media Camp 2009 |
| o_saltan, netocrat, ... | 13 | journalists (7), zp (6) | Журналисты, много из Запорожья |
| b2blogger, maxzalevski, ... | 7 | seo (5), belseo (5), web-marketing (4) | Веб-маркетологи и SEO-специалисты |
Еще о четырех сообществах трудно что-то сказать на основе списков. Я, например, попал в сообщество, из которого многи ретвитили о tweetingplaces, одном моем проекте. Но общих названий списков у нас, кроме ukrtweet, нет.
Донецк
| Участники | Всего участников | Метки | Комментарии |
|---|---|---|---|
| quantizer, alderko, ... | 21 | donntu (10) | Одно сообщество из ДонНТУ |
| decoy, andrulik, ... | 21 | cnc-donetsk (9) | Многие бывшие на встречах "Кофе и код" |
| medialex, iammarat, ... | 13 | christians (13) | Верующие |
| lapidarius, kolgushev, ... | 11 | seo (2), medianext-ua (2) | Имеющие отношение к новым медиа |
| meesix, bezlik, ... | 9 | donntu (2) | Второе сообщество имеющее отношение к ДонНТУ |
| alexeyosipenko, a_djo, ... | 8 | donetsk-rubyists (5), cnc-donetsk (3) | Поклонники Ruby, также бывшие на КиК |
Что интересно, olchik_terl и lancerenok, которые упоминались ранее, и у кого PageRank был больше, чем у других людей, которые так же часто упоминаются, попадают в активные сообщества, которые плохо описываются списками. Они же больше общаются со всей группой, а не внутри профессиональных сообществ.
Упражнения
Twitter, благодаря своему API, предоставляет плодородное поля для добычи и анализа информации о социальных графах. Вот несколько упражнений для тех, кто захочет больше покопаться.
- Какими средствами в группе чаще всего пользуются чтобы твитить (web, TweetDeck, Echofon,...)?
- Упоминались центральности. Изобразить betweenness_centrality в зависимости от eigenvector_centrality при помощи NetworkX.
- Получить влияния извне взвешенные через PageRank.
- С помощью кода книги «Программируем коллективный разум» выделить кластеры в группе не на основе графа, а на основе общих списков.
Используемые библиотеки
BeautifulSoup
для парсинга HTML
tweepy
интерфейс для доступа к Twitter API
NetworkX.
для работы с графами
Matplotlib
позволяет рисовать графики и диаграммы
igraph
пакет для работы с графами, есть интерфейс на Python (здесь не использовался, но упоминался)










{kind=link}
{kind=link}