Пока никто не сказал: «Зачем придумывать велосипед?», и в этот велосипед не полетели помидоры, сразу говорю, что средняя длина русского слова давно посчитана и составляет 5.28 символа. Вот ссылка на источник. А этот топик меня сподвигло написать следующее. При обсуждении моего предыдущего поста хабраюзеры stetzen и alienator высказали предположение, что средняя длина слова у различных авторов будет отличаться в зависимости от их стиля изложения, а может быть каких-то анатомических различий, уж не знаю. Кстати, попробуйте угадать среднюю длину чего больше всего ищут в гугле. В общем я решил проверить так ли это на самом деле.
Ниже лежит исходник программы, которая считает общее количество слов в тексте, а также среднюю длину слова. Программа написана на perl.
Практически все тексты, которыми я пользовался взяты с библиотеки Мошкова. Вот что у меня получилось.
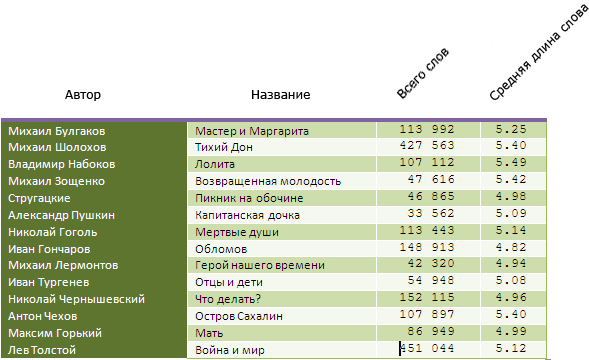
Выводы, на сколько отличается средняя длина слова у разных авторов делайте сами.
Ниже лежит исходник программы, которая считает общее количество слов в тексте, а также среднюю длину слова. Программа написана на perl.
use strict;
use locale;
use POSIX qw (locale_h);
setlocale(LC_CTYPE, 'ru_RU.CP1251');
setlocale(LC_ALL, 'ru_RU.CP1251');
open (TEXT, "<text.txt");
undef $/;
my $text = <TEXT>;
close(TEXT);
my @words = $text =~ m/[А-Я]+/ig;
open(OUT, ">out.txt");
my ($count, $sum);
foreach(@words){
$count++;
$sum += length($_);
}
print OUT "Всего слов: $count\nСредняя длина слова: ".($sum/$count);
close(OUT);
Практически все тексты, которыми я пользовался взяты с библиотеки Мошкова. Вот что у меня получилось.
Выводы, на сколько отличается средняя длина слова у разных авторов делайте сами.








