
В комментах часто жалутся на обилие нежелательного контента на главной. Посты же не могут нравится всем сразу. Duh…
Вывод один — надо фильтровать.
С картинками.
Вместо вступления
Про Y!P уже писали: раз, два, and more. Напишем еще раз, лишним не будет. Инструмент поистине впечатляющий.
А почему собственно был выбран Y!P, когда данный функционал уже реализован во многих rss ридерах?
Просто потому что это очень интересно — заниматься чем-то новым и таким близким к *nix философии. Кроме того после фильтрации через Y!P вы получаете только полезный траффик из ленты, не нагружая свой канал лишними данными.
Новый движок
Не так давно Y!P обзавелся движком версии два: Yahoo! Pipes V2 engine.
Если коротко:
- движок V1 через некоторое прекратит существование
- V2 позволит добавить новые фичи
- V2 отличается большей скоростью
- у V2 скорее всего куча багов (это неофициальный релиз)
Получение ленты
Все начинается с rss ленты. Однако Хабралента не подходит для Y!P. Не слишком заморачиваясь подробностями, берем ленту с feedburner'a:
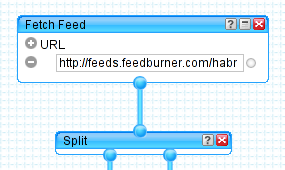
На рисунке представлен модуль Fetch Feed. Его задача — взять ленту с указанного адреса и передать дальше в пайп. А дальше, как видно, следует модуль Split, который разделяет одну ленту на две совершенно одинаковые.
Это чтобы была избыточность для отказоустойчивости?
Нет, это нужно для хитрой фильтрации: в левом канале отрезается все, что не нужно, а в правом остается только то, что нужно.
Фильтрация
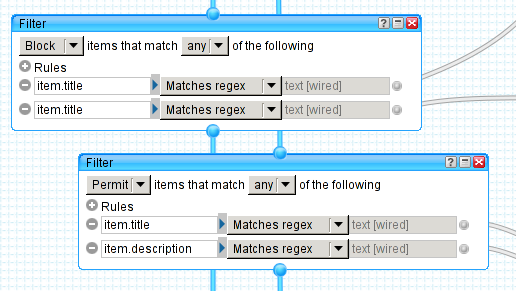
Верхний модуль блокирует записи по двум RegExp'ам, а нижний разрешает записи по двум другим.
А что такое RegExp?
Про RegExp'ы eng, рус, а также хороший гайд по теме.
Чтобы наши модули фильтров не превращались в громадных монстров, наши ключевые слова для фильтрации подводятся отдельно (поле text [wired] c подозрительными серыми связями). А пока стоит остановиться на левой части модуля. Из выпадающего списка можно выбрать интересующий элемент записи. Для нашей задачи (блокировка записей) отлично подойдет поле item.title, ведь именно по заголовку в первую очередь записи и отсеиваются. Поле item.description содержит тело записи и используется в фильтре для оставления интересующих нас тем. Например ты, %username%, заблокировал слово Microsoft©, но разрешил слово Linux. В таком случае, если в посте с заголовком «Microsoft берет новые высоты» будет написано «linux то все равно круче», то данная запись попадет прямиком к тебе в rss читалку.
Оформление результата
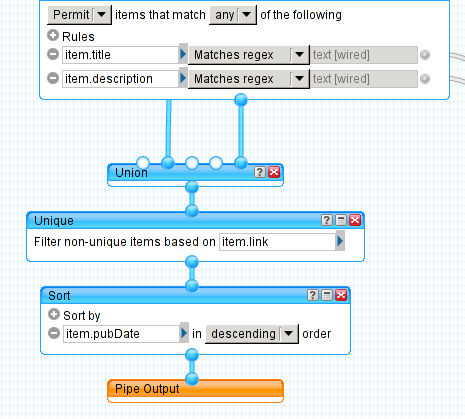
После вырезания\оставления записей, необходимо две ленты снова объединить в одну. Делает это элемент Union, у которого аж 5 входов (так жалко растрачивать неиспользуемые входы). Теперь у нас снова одна лента, в которой вполне могли завестить дупликаты. Вывести этих нежелательных паразитов нам поможет модуль Unique: на основе поля item.link он просмотрит все записи и изымет лишние. Осталось только навести красоту, отсортировав записи по какому-нибудь критерию. На картинке записи сортируются по убыванию даты публикации (новые в начале). Самый главный модуль в конце любого пайпа — Output. Именно на нем должен закончится наш проект. Ну так собственно и получилось. Кликнув на модуль Output, можно насладиться результатом стараний:
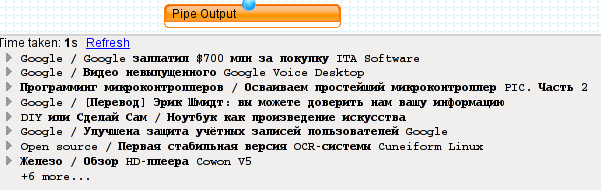
Так, а где-же шаблоны для отсеивания записей?
Шаблоны
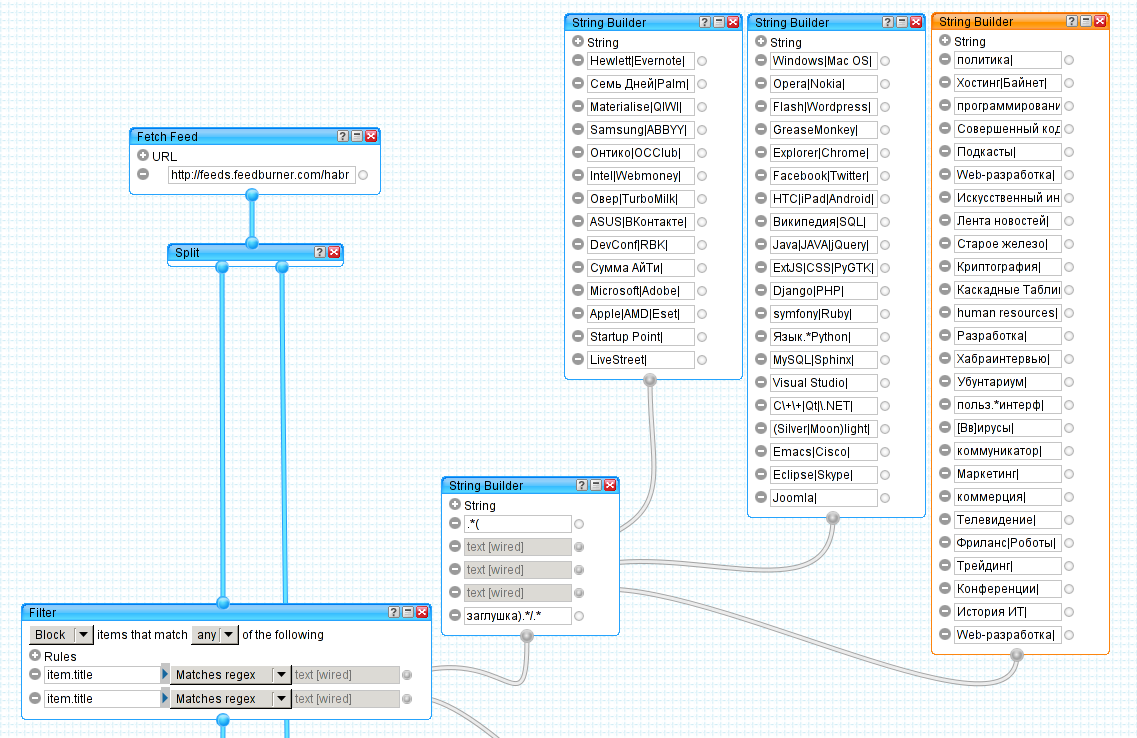
Так выглядят шаблоны для удаления постов. Три большие String Builder'a нужны просто для красоты (можно всё засунуть в один). Кроме того разделение помогает с некоторого рода систематизацией шаблонов. Все записи отделются друг от друга вертикальной чертой, и это очень важный момент. String Builder попросту берет все поля и соединяет их в одну строку. Маленький String Builder собирает всю информацию из больших, а затем оборазчивает в подходящую обертку. Как известно, заголовки постов выглядят на Хабре следующим образом: «блог / пост», поэтому в данном случае все шаблоны нацелены на фильтр определенных блогов. Слово «заглушка» помогает нам избежать ситуации, когда в конце блока ИЛИ не окажется ничего ( microsoft|linux|freebsd| ), что будет отфильтровывать абсолютно все посты. Посмотреть на получившийся RegExp можно в поле debugger после клика на маленьком string builder'e:

Второй шаблон для запрещающего фильтра немного проще, и блокирует он определенные посты (из любых блогов):
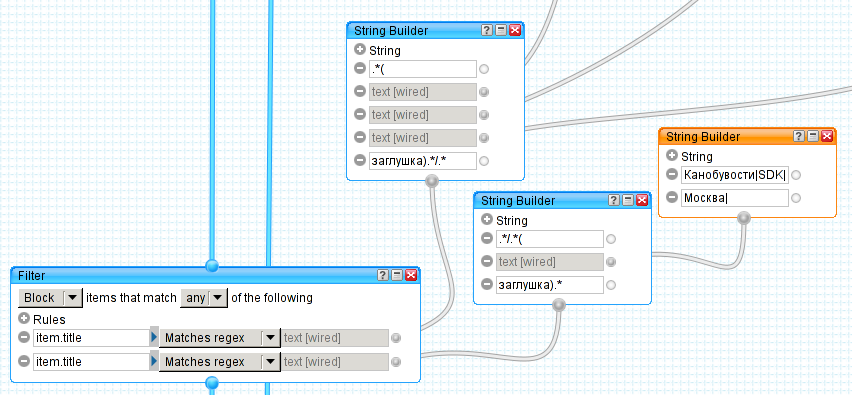
Разрешающий фильтр выглядит заметно меньше, но не менее важен:
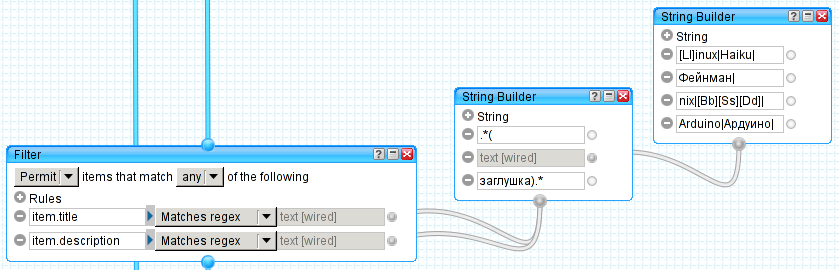
Ключевые слова из String Builder'a он будет искать как в заголовке, так и в теле поста. Эти элементы помогут нам не упустить важный топик из-за жесткой фильтрации.
А дальше что?
Подписываемся на rss или atom получившейся ленты и конечно же PROFIT.
Вместо заключения
Надеюсь данная статья поможет тебе, %username%, освоить Yahoo.Pipes и реализовать там свои идеи.
Ссылка на пайп из статьи: habrapipe







