
Часть первая. Классификация/локализация, обнаружение объектов и слежение за объектом
Компьютерным зрением обычно называют научную дисциплину, которая даёт машинам способность видеть, или более красочно, позволяя машинам визуально анализировать своё окружение и стимулы в нём. Этот процесс обычно включает в себя оценку одного или нескольких изображений или видео. Британская ассоциация машинного зрения (BMVA) определяет компьютерное зрение как «автоматическое извлечение, анализ и понимание полезной информации из изображения или их последовательности».
Термин понимание интересно выделяется на фоне механического определения зрения — и демонстрирует одновременно и значимость, и сложность области компьютерного зрения. Истинное понимание нашего окружения достигается не только через визуальное представление. На самом деле визуальные сигналы проходят через оптический нерв в первичную зрительную кору и осмысливаются мозгом в сильно стилизованном смысле. Интерпретация этой сенсорной информации охватывает почти всю совокупность наших естественных встроенных программ и субъективного опыта, то есть как эволюция запрограммировала нас на выживание и что мы узнали о мире в течение жизни.
Этот фрагмент взят из недавней публикации, которую составила наша научно-исследовательская группа в области компьютерного зрения. В ближайшие месяцы мы опубликуем работы на разные темы исследований в области Искусственного Интеллекта — о его экономических, технологических и социальных приложениях — с целью предоставить образовательные ресурсы для тех, кто желает больше узнать об этой удивительной технологии и её текущем состоянии. Наш проект надеется внести свой вклад в растущую массу работ, которые обеспечивают всех исследователей информацией о самых современных разработках ИИ.
Введение
Компьютерным зрением обычно называют научную дисциплину, которая даёт машинам способность видеть, или более красочно, позволяя машинам визуально анализировать своё окружение и стимулы в нём. Этот процесс обычно включает в себя оценку одного или нескольких изображений или видео. Британская ассоциация машинного зрения (BMVA) определяет компьютерное зрение как «автоматическое извлечение, анализ и понимание полезной информации из изображения или их последовательности».
Термин понимание интересно выделяется на фоне механического определения зрения — и демонстрирует одновременно и значимость, и сложность области компьютерного зрения. Истинное понимание нашего окружения достигается не только через визуальное представление. На самом деле визуальные сигналы проходят через оптический нерв в первичную зрительную кору и осмысливаются мозгом в сильно стилизованном смысле. Интерпретация этой сенсорной информации охватывает почти всю совокупность наших естественных встроенных программ и субъективного опыта, то есть как эволюция запрограммировала нас на выживание и что мы узнали о мире в течение жизни.
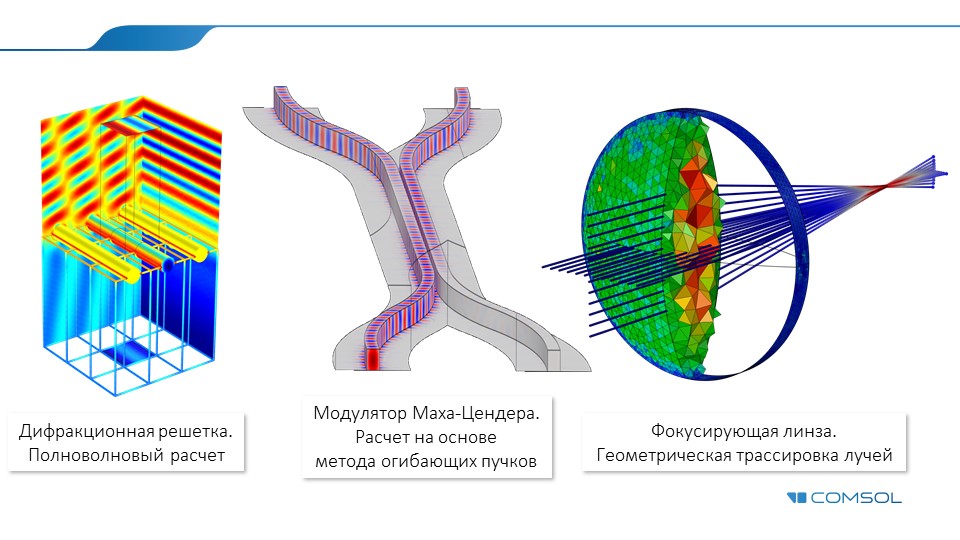




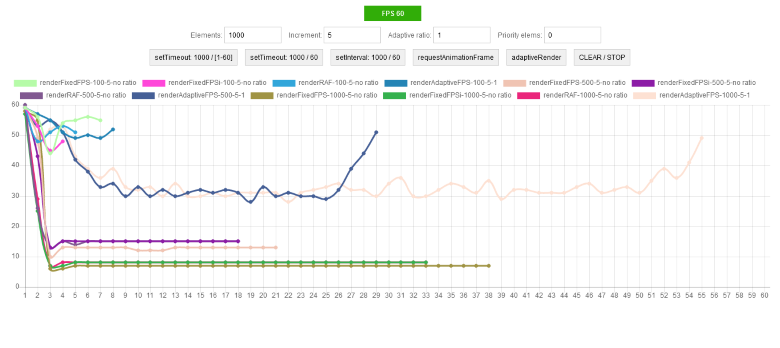

 Я написал уйму плагинов на jQuery. Если посмотреть код всех плагинов, сортируя их по дате публикации на github, то можно проследить эволюцию кода. Ни в одном из этих плагинов не соблюдены все рекомендации, которые будут описаны ниже. Все что будет описано, лишь мой личный опыт, накопленный от проекта к проекту.
Я написал уйму плагинов на jQuery. Если посмотреть код всех плагинов, сортируя их по дате публикации на github, то можно проследить эволюцию кода. Ни в одном из этих плагинов не соблюдены все рекомендации, которые будут описаны ниже. Все что будет описано, лишь мой личный опыт, накопленный от проекта к проекту. 

